

دوره 10، شماره 2 - ( تابستان 1403 )
جلد 10 شماره 2 صفحات 219-206 |
برگشت به فهرست نسخه ها



Ethics code: IR.MUMS.REC.1401.038
![]()
![]()
![]()
Download citation:
BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:



BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:
Tahmasbi H, Besharati R. Developing a Mobile Application for Early Prediction of Hypertension in Children. JMIS 2024; 10 (2) :206-219
URL: http://jmis.hums.ac.ir/article-1-502-fa.html
URL: http://jmis.hums.ac.ir/article-1-502-fa.html
طهماسبی حمیدرضا، بشارتی رضا. ارائه مدل و برنامه کاربردی مبتنی بر تلفن همراه برای پیشبینی زودهنگام فشار خون بالا در کودکان. اطلاعرسانی پزشکی نوین. 1403; 10 (2) :206-219



گروه مهندسی کامپیوتر، دانشکده مهندسی، واحد کاشمر، دانشگاه آزاد اسلامی، کاشمر، ایران.
متن کامل [PDF 5823 kb]
(1065 دریافت)
| چکیده (HTML) (3139 مشاهده)
متن کامل: (1363 مشاهده)
مقدمه
فشار خون بالا در بزرگسالی یک عامل بسیار رایج در افزایش خطر حمله قلبی، بیماریهای قلبیعروقی و مرگومیر است [1-4]. شواهد زیادی وجود دارد که نشان میدهد فشار خون بالا و بیماریهای قلبیعروقی در بزرگسالی از دوران کودکی منشأ میگیرند [5، 6]. امروزه تعداد فزایندهای از کودکان و نوجوانان به دلایلی از قبیل شیوه زندگی، تغذیه، عدم فعالیت فیزیکی، اضافهوزن و چاقی، دچار فشار خون بالا میشوند. بررسی انجامشده در مطالعه [7] افزایش قابلتوجه در ابتلای کودکان و نوجوانان به فشار خون بالا در دو دهه اخیر در جهان را گزارش میکند. در ایران نیز در مطالعه جامعی که انجام شده [8]، شیوع فشار خون در کودکان ایرانی بالا گزارش شده و باتوجهبه افزایش سالبهسال آن، بر نیاز به توجه بیشتر به این عارضه در کودکان تأکید شده است. فشار خون بالا حتی در دوران کودکی خطر ابتلا به تصلب شرایین و بیماریهای قلبیعروقی را افزایش میدهد [5]. فشار خون کودکان نیازمند اقدامات برنامهریزیشده برای به حداقل رساندن افزایش فشار خون در بزرگسالان و بیماریهای قلبیعروقی در آینده است [8].
باتوجهبه پیامدهای درازمدت فشار خون بالای کنترلنشده در کودکان برای سلامتی، شناسایی زودهنگام کودکان پرفشار خون و یا در معرض خطر ابتلا به فشار خون و شروع پیشگیری از فشار خون بالا در اوایل زندگی ضروری است و این موضوع به یکی از مهمترین چالشهای بهداشت عمومی در سراسر جهان تبدیل شده است [3، 7]. فشار خون بالا معمولاً بدون علامت است و باعث میشود شانس تشخیص زودهنگام آن بهشدت کاهش یابد [9]. در سالهای اخیر استفاده از روشهای یادگیری ماشین بهعنوان یک راهکار مفید و مؤثر در پیشبینی و کنترل بیماریها از اهمیت خاصی برخوردار شده است. یادگیری ماشین شاخهای از هوش مصنوعی است که علوم کامپیوتر، آمار و نظریه تصمیم را برای یادگیری و استخراج الگوهای پیچیده از حجم انبوهی از دادهها ترکیب میکند. مطالعات انجامشده در 2 دهه اخیر، سودمند بودن استفاده از یادگیری ماشین برای تشخیص و پیشبینی فشار خون را نشان میدهند. بهطوریکه مورد توجه بسیاری از پژوهشگران قرار گرفته است [2، 4، 10-12]. بهعنوان مثال آمبیکا و همکاران [13] با توسعه روش یادگیری ماشین بردار پشتیبان، یک سیستم پشتیبان تصمیم برای پیشبینی ابتلا به فشار خون بالا از روی اطلاعات سوابق پزشکی و شیوه زندگی افراد با دقت 91/88 درصد پیشنهاد کردند.
ایسلام و همکاران [14] نیز از روشهای یادگیری ماشین درخت تصمیم، جنگل تصادفی، رگرسیون خطی، تقویت گرادیان، تقویت گرادیان شدید و روش آنالیز تشخیص خطی برای پیشبینی فشار خون بالا و همچنین شناسایی عوامل مؤثر بر این عارضه استفاده کردند. ارزیابی آنها نشان داد روشهای رگرسیون خطی، تقویت گرادیان شدید و آنالیز تشخیص خطی با دقتی حدود 90 درصد، بهتر از روشهای جنگل تصادفی و درخت تصمیم بوده و ویژگیهای سن و شاخص توده بدنی، عوامل مؤثر در فشار خون بالا در مجموعه داده موردبررسی بودهاند. در تحقیق مشابه، آنح و همکاران [15] از روشهای درخت تصمیم، بیزن ساده، نزدیکترین k همسایه، شبکههای عصبی مصنوعی، ماشین بردار پشتیبان، جنگل تصادفی، رگرسیون خطی، رأیگیری و تقویت گرادیان شدید برای پیشبینی فشار خون بالا استفاده کردند. یافتههای آنها بیانگر عملکرد بهتر روش جنگل تصادفی نسبت به سایر روشهای مقایسهشده بود.
الکعبی و همکاران [16] با استفاده از 3 روش درخت تصمیم، جنگل تصادفی و رگرسیون لجستیک، مدلی برای پیشبینی فشار خون بالا پیشنهاد کردند. در این مطالعه، روش جنگل تصادفی با دقت پیشبینی 82/1 درصد، کارایی بهتری در تشخیص وجود فشار خون بالا داشت. ژائو و همکاران [17] با استفاده از روش یادگیری جنگل تصادفی روشی برای پیشبینی فشار خون بالا از روی ویژگیهایی که از افراد و بدون نیاز به ابزار تخصصی خاصی به دست میآید، ارائه کردند. دقت این روش حدود 82 درصد بود و ویژگیهای سن، دور کمر، شاخص توده بدنی و سابقه خانوادگی فشار خون را بهعنوان عوامل اصلی فشار خون بالا در مجموعه داده موردنظر شناسایی کرده است.
چای و همکاران [18] روشهای مختلف یادگیری ماشین را برای تشخیص فشار خون بالا در نوجوانان 13 تا 17 ساله بررسی کردند. یافتههای آن ها نشان داد روش یادگیری تقویت گرادیان سبک در مقایسه با سایر روشها برای تشخیص فشار خون بالا عملکرد بهتری داشته است. آنها همچنین در مطالعه دیگری [19] با توسعه روش یادگیری شبکههای عصبی مصنوعی، مدلی با دقت 76 درصد در پیشبینی فشار خون بالا در نوجوانان پیشنهاد کردند. دهقاندار و همکاران [20] از شبکهها عصبی مصنوعی برای تشخیص فشار خون بالا و چاقی در دانشآموزان 7 تا 18 ساله استفاده کردند. این روش، فشار خون سیستولیک را با دقت 74 درصد و فشار خون دیاستولیک را با دقت 79 درصد تشخیص داد.
برخی از مدلهای موفق پیشنهادی برای تشخیص و پیشبینی فشار خون بالا از ترکیب نتایج خروجی چند روش یادگیری مختلف استفاده کردهاند. این رویکرد ترکیبی یک راهکار سودمند برای بهبود دقت دستهبندی است و مطالعات مختلف نشان دادهاند ترکیب روشهای یادگیری در مقایسه با هریک از روشهای یادگیری استفادهشده در ترکیب، دقت بیشتری داشته [21] و نقش مؤثری در افزایش دقت تشخیص فشار خون بالا و عوامل مؤثر بر آن دارد [22، 23]. فیتریانی و همکاران [23] روشی با ترکیب الگوریتمهای یادگیری ماشین بردار پشتیبان، شبکههای عصبی مصنوعی چندلایه و ماشین درخت تصمیم و یک مدل رگرسیون لجستیک برای پیشبینی فشار خون ارائه کردند. این روش برای تشخیص فشار خون در مردان دقتی برابر 85/73 درصد و در زنان دقتی برابر 75/78 درصد داشته است.
کانگائی و همکاران [24] با استفاده از روشهای درخت تصمیم، جنگل تصادفی و رگرسیون خطی یک مدل ترکیبی برای پیشبینی فشار خون بالا پیشنهاد کردند. در این مدل، هریک از 3 روش یادگیری بهصورت مستقل عمل پیشبینی را انجام داده و نتیجه نهایی ازطریق میانگین نتایج آنها به دست میآید. یک مدل ترکیبی نیز توسط فنگ و همکاران [25] پیشنهاد شد که نتایج خروجی 2 روش یادگیری نزدیکترین k همسایه و تقویت گرادیان سبک را برای پیشبینی فشار خون بالا براساس میانگین وزنی آنها ترکیب میکند. ارزیابی آنها نشان داد این مدل دقتی حدود 86 درصد دارد.
باتوجهبه ضرورت تشخیص زودهنگام یا پیشبینی مداوم فشار خون در دوران کودکی برای به حداقل رساندن خطر فشار خون بالا و عوارض آن، هدف این مقاله ارائه مدلی توسعهیافته با استفاده از روشهای یادگیری ماشین برای تشخیص و پیشبینی فشار خون بالا در کودکان دبستانی و پیادهسازی مدل پیشنهادی در قالب یک برنامه کاربردی مبتنی بر تلفن همراه برای استفاده والدین کودکان است. در مدل پیشنهادی، عمل تشخیص و پیشبینی فشار خون بالا با ترکیب نتایج حاصل از 3 روش یادگیری ماشین متداول با استفاده از تئوری ترکیب شواهد دمپستر شافر انجام شد. اغلب روشهای پیشنهادی در مطالعات مرتبط، نمونه ورودی را به یکی از 2 دسته فشار خون نرمال و فشار خون بالا دستهبندی میکنند. درحالیکه در مدل ارائهشده در این مقاله، باتوجهبه دستورالعمل آکادمی پزشکی اطفال آمریکا [26]، نمونههای ورودی به یکی از 4 دسته نرمال، پیش فشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 دستهبندی میشوند. امروزه گوشیهای تلفن همراه به بخشی جداییناپذیر از زندگی اکثر مردم تبدیل شدهاند. تشخیص و پیشبینی فشار خون بالا به کمک گوشی تلفن همراه به دلیل سهولت استفاده برای بسیاری از مردم، میتواند توانایی نظارت بر فشار خون را افزایش دهد. در برنامه کاربردی پیادهسازیشده، والدین میتوانند با ورود اطلاعاتی که بهراحتی از کودکان و بدون نیاز به ابزار تخصصی خاصی قابلدستیابی است بر فشار خون فرزندان خود کنترل و نظارت مداوم داشته باشند.
مواد و روشها
این پژوهش از نوع کاربردیتوسعهای بود که در آن ابتدا مدلی برای پیشبینی فشار خون بالا در کودکان دبستانی با استفاده از روشهای یادگیری ماشین ارائه شد و سپس با استفاده از این مدل پیشنهادی، یک برنامه کاربردی قابلاستفاده در گوشی تلفن همراه برای تشخیص و پیشبینی فشار خون بالا در کودکان طراحی و پیادهسازی شد. نمونه آماری 1287 نفر از دانشآموزان بین 7 تا 13 ساله دبستانهای شهر کاشمر شامل 542 پسر و 745 دختر بودند که مقادیر مربوط به 19 ویژگی مؤثر در فشار خون این دانشآموزان با رضایت کتبی والدین آنها جمعآوری شد. این ویژگیها در جدول شماره 1 مشاهده میشوند. مقادیر ویژگیهای جنسیت، سن، میزان مصرف نمک، سابقه مصرف داروهای مؤثر بر فشار خون، سابقه بیماریهای دیابت، قلبی، کلیوی و سایر بیماریها و سابقه خانوادگی پرفشاری خون ازطریق پرسشنامه تکمیلشده توسط والدین دانشآموزان، به دست آمد. قد هر دانشآموز در حالت کاملاً ایستاده بدون کفش و کلاه، برحسب سانتیمتر و وزن هر دانشآموز بدون کفش و با حداقل لباس ممکن برحسب کیلوگرم، اندازهگیری شد. مقدار اعشاری بهدستآمده برای وزن، به نزدیکترین عدد صحیح قبل و یا بعد آن گرد شد. شاخص توده بدنی بهصورت نسبت وزن برحسب کیلوگرم به مجذور قد برحسب متر مربع برای هر دانشآموز محاسبه شد. نبض نیز با استفاده از کورنومتر برای مدت 1 دقیقه اندازهگیری شد.
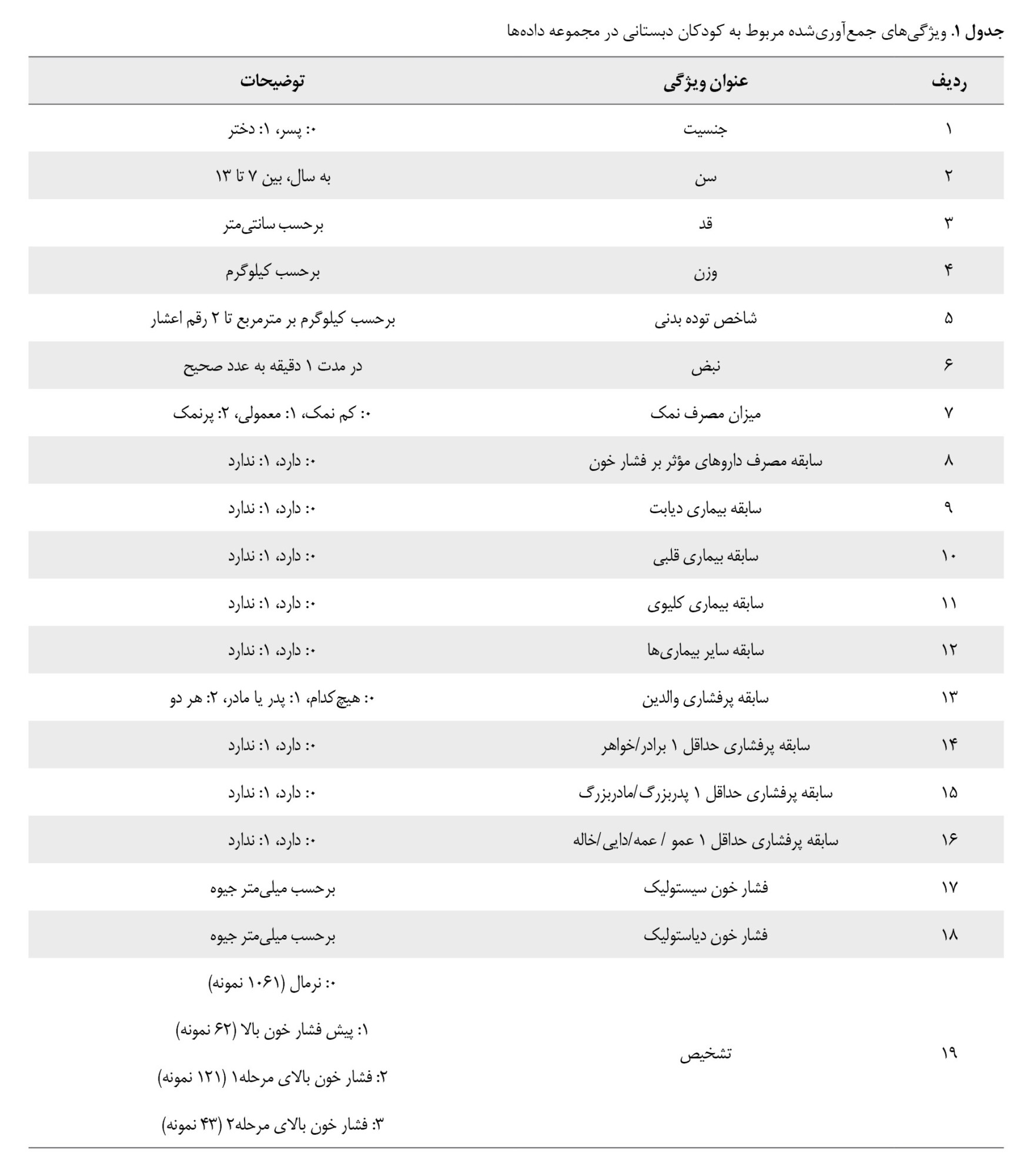
فشار خون سیستولیک و دیاستولیک برحسب میلیمتر جیوه، در وضعیت نشسته و پس از استراحت 5 دقیقهای فرد دانشآموز، 2 بار و به فاصله 5 دقیقه با دستگاه فشارسنج عقربهای اندازهگیری شد. میانگین 2 بار اندازهگیری، بهعنوان فشار خون نهایی فرد در نظر گرفته شد. از مقادیر فشار خون سیستولیک و دیاستولیک برای تعیین مقدار ویژگی تشخیص توسط فرد خبره و دستهبندی هر دانشآموز به یکی از 4 دسته فشار خون نرمال، پیش فشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 باتوجهبه دستورالعمل آکادمی پزشکی اطفال آمریکا [26] (جدول شماره 2) استفاده شد و کاربرد دیگری در این پژوهش نداشته است. براساس این دستهبندی، تعداد نمونههای متعلق به هر دسته در ردیف 19 جدول شماره 1 مشاهده میشود.
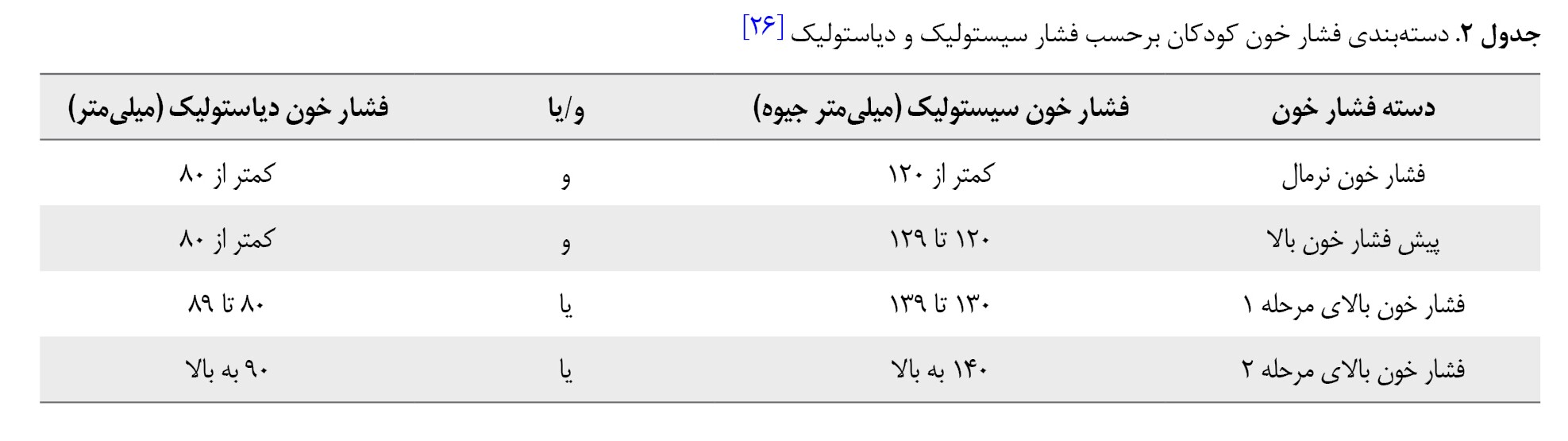
کیفیت دادهها و آمادهسازی آنها نقش مهمی در افزایش کارایی مدل یادگیری دارند [13]. بنابراین پیشپردازش دادههای جمعآوریشده بهعنوان اولین گام در مدل پیشنهادی مورد توجه قرار گرفته است. در این مرحله، برای جانشینی مقادیر نامشخص از روش میانه/مد [27] استفاده شد. برایناساس، در اطلاعات جمعآوریشده مربوط به 58 دانشآموز، مقدار ویژگی میزان مصرف نمک نامشخص بود که مقدار «مصرف طبیعی» که بیشترین تکرار را در بین مقادیر این ویژگی در مجموعه داده دارد، برای آنها منظور شد. مجموعه داده جمعآوریشده نامتوازن است. بهطوریکه تعداد نمونههای دارای فشار خون نرمال نسبت به سایر نمونهها بسیار بیشتر هستند. مسئله نامتوازن بودن دادهها در اکثر دادههای پزشکی وجود دارد و معمولاً باعث میشود دقت مدل یادگیری تحت تأثیر قرار گرفته و نمونههای متعلق به دسته اقلیت بهعنوان نمونههای دسته اکثریت دستهبندی شوند [23، 28]. برای غلبه بر این مشکل و متوازنسازی دادهها در مدل پیشنهادی از روش معروف SMOTE استفاده شد. در این روش، برای دستههای با تعداد نمونههای کمتر، نمونههای جدیدی در همسایگی نمونههای متعلق به آن دستهها تولید شده و درنتیجه بین تعداد نمونههای متعلق به هریک از دستهها، توازن ایجاد میشود. با متوازنسازی دادههای جمعآوریشده، تعداد نمونههای دستههای پیشفشار خون بالا، فشار خون مرحله 1 و فشار خون مرحله 2 به ترتیب به 1054، 1064 و 1032 نمونه افزایش یافت. پس از متوازنسازی دادهها، با استفاده از روش نرمالسازی متداول حداقل حداکثر، مقادیر همه ویژگیها به مقادیری در بازه 1-0 تبدیل شدند.
پس از پیشپردازش دادهها، ساخت و یادگیری مدل انجام شد. در مدل پیشنهادی بهمنظور افزایش دقت در تشخیص و پیشبینی فشار خون بالا از رویکرد ترکیبی استفاده شد. ابتدا 3 روش یادگیری ماشین متداول استفادهشده در تشخیص و پیشبینی فشار خون بالا [2، 4، 12]، شامل شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی، بهصورت مجزا روی مجموعه دادهها اعمال و عمل پیشبینی انجام شد. بدین منظور از ماژولهای نرمافزار دادهکاوی Weka نسخه 3/7/8 با پارامترهای پیشفرض استفاده شد. سپس نتایج حاصل از 4 روش یادگیری مذکور با استفاده از تئوری ترکیب شواهد دمپستر شافر جهت پیشبینی نهایی با هم ترکیب شدند. ویژگیهای بازیابی صریح عدم قطعیت و قاعده ترکیب شواهد در این تئوری باعث استفاده از آن در مدل پیشنهادی شده است. در تئوری ترکیب شواهد دمپستر شافر، باور مقداری است که برای بیان قطعیت یک گزاره یا رویداد به کار میرود. قاعده ترکیب شواهد در این تئوری، 2 بدنه شواهد مستقل تعریفشده در یک چارچوب مشاهدات را با هم ترکیب کرده و به 1 بدنه شواهد تبدیل میکند [21]. این تئوری، نتایج خروجی روشهای یادگیری را بهعنوان شواهد در نظر گرفته و با رویهمگذاری آنها، یک تابع باور تولید میکند که براساس آن، پیشبینی نهایی انجام میشود. در مدل پیشنهادی، 4 دسته فشار خون نرمال، پیشفشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 بهعنوان چارچوب مشاهدات در نظر گرفته شدند. خروجی روشهای یادگیری بهعنوان شواهد با هم ترکیب شده و براساس مقادیر باور حاصلشده، دسته با بزرگترین مقدار باور بهعنوان دسته نمونه ورودی تعیین میشود. در صورت وجود عدم قطعیت برای پیشبینی فشار خون در نمونه ورودی، این نمونه به هیچ دستهای تعلق نمییابد. روش ترکیبی با زبان برنامهنویسی پایتون پیادهسازی شد.
برای ارزیابی کارایی مدل ارائهشده همانند اغلب مطالعات مشابه [14، 15، 17، 18، 23] از روش اعتبارسنجی متقابل 10 تکه برابر استفاده شده است. معیارهای ارزیابی شامل دقت، حساسیت و ویژگی بوده که بهصورت فرمول شماره 1 محاسبه میشوند.
.jpg)
در این روابط، m بیانگر تعداد دستهها میباشد. TPi (True Positive) تعداد نمونههای متعلق به دسته i است که درست تشخیص و دستهبندی شدهاند.TNi (True Negative) تعداد نمونههای متعلق به سایر دستهها است که در دسته i دستهبندی نشدهاند. FPi (False Positive) تعداد نمونههایی است که به اشتباه در دسته i دستهبندی شدهاند. FNi (False Negative) نیز تعداد نمونههای متعلق به دسته i است که اشتباهی در دسته دیگری دستهبندی شدهاند.
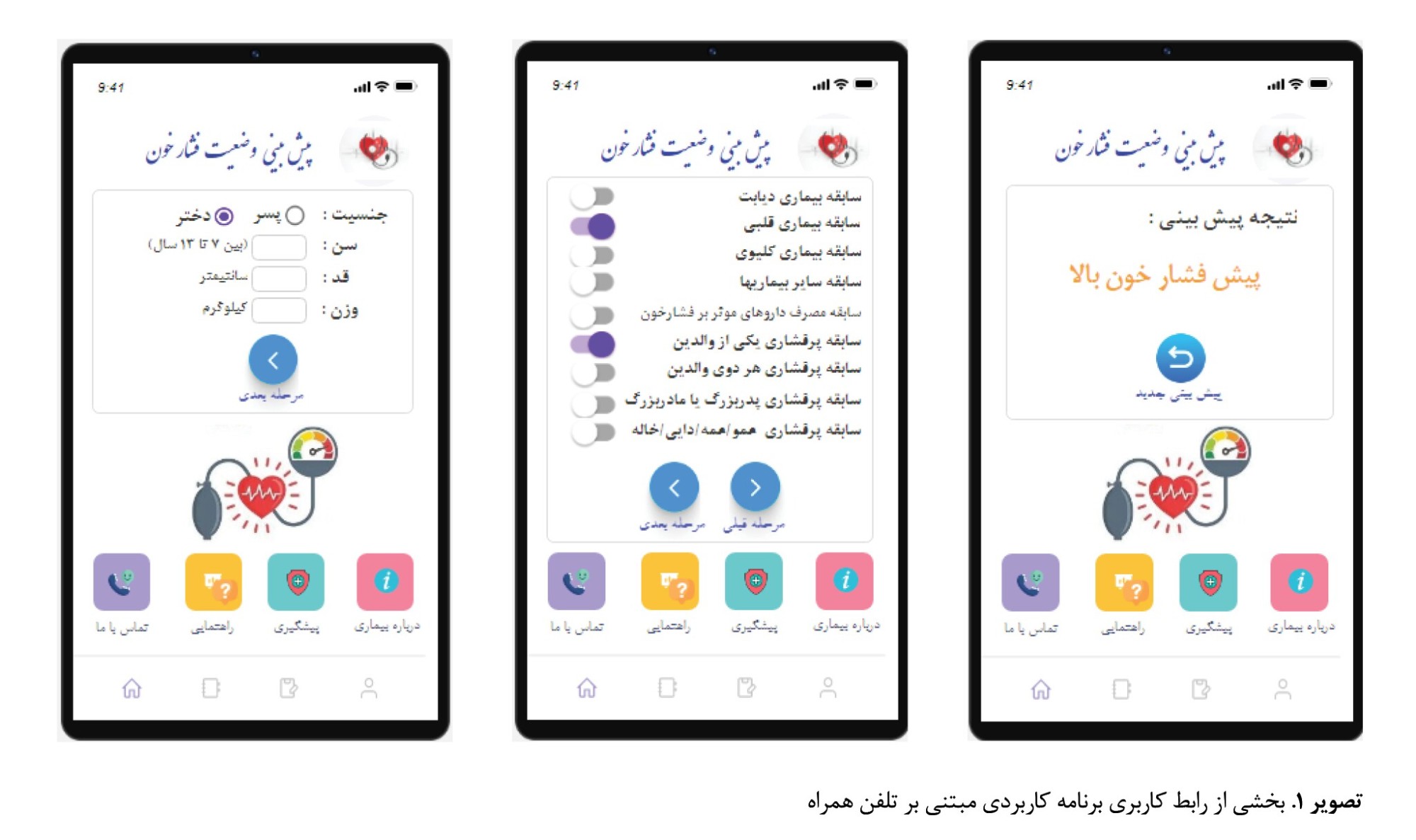
مدل ارائهشده در قالب یک برنامه کاربردی اندرویدی قابلاستفاده بر روی گوشی تلفن همراه، با استفاده از چارچوب ساخت نرمافزار کیوی (Kivy) و زبان برنامهنویسی پایتون پیادهسازی شد. در این برنامه کاربردی، کاربر اطلاعات درخواستشده را وارد کرده و سپس با کلیک بر روی مشاهده نتیجه، نتیجه پیشبینی را در یکی از دستههای نرمال، پیشفشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 مشاهده میکند.
یافتهها
تعداد نمونههای دستههای پیشفشار خون بالا، فشار خون مرحله 1 و فشار خون مرحله 2 پس از متوازنسازی در مدل پیشنهادی به ترتیب از 62، 121 و 43 به 1054، 1064 و 1032 نمونه افزایش یافت.
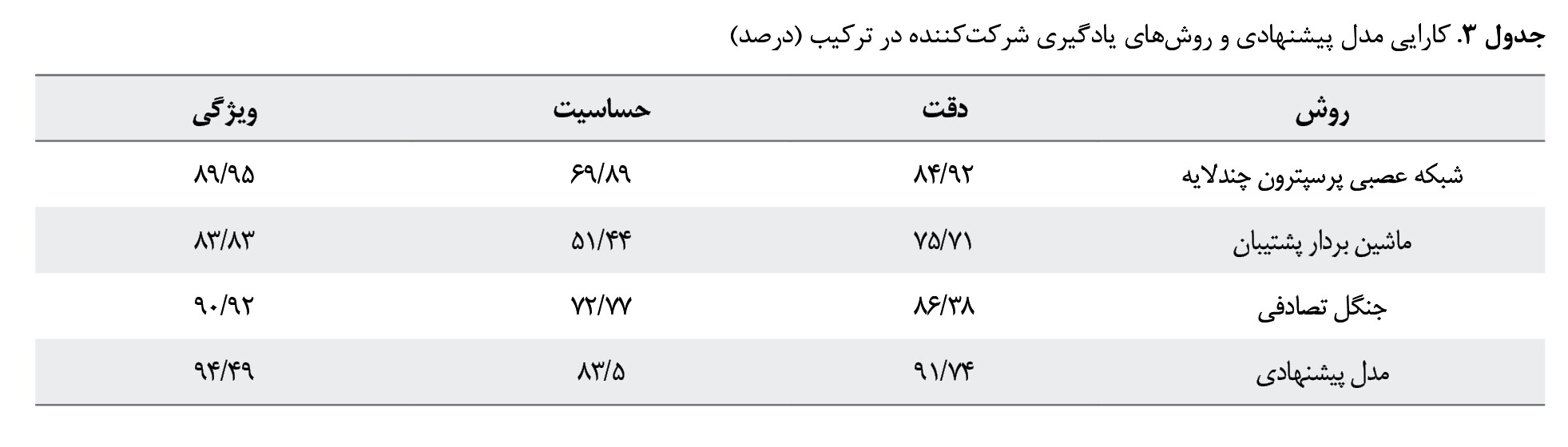
جدول شماره 3 نتایج بهدستآمده برای هریک از معیارهای دقت، حساسیت و ویژگی در مدل پیشنهادی و همچنین روشهای یادگیری شرکتکننده در ترکیب شامل شبکه عصبی پرسپترون چندلایه، ماشین بردار پشتیبان و جنگل تصادفی را نشان میدهد. مقادیر پررنگ در این جدول بیانگر بیشترین مقدار در هر معیار هستند. این یافتهها نشان میدهند مقادیر بهدستآمده از هر سه معیار موردمقایسه در مدل پیشنهادی از 3 روش یادگیری استفادهشده در ترکیب، بهطور چشمگیری بیشتر هستند.
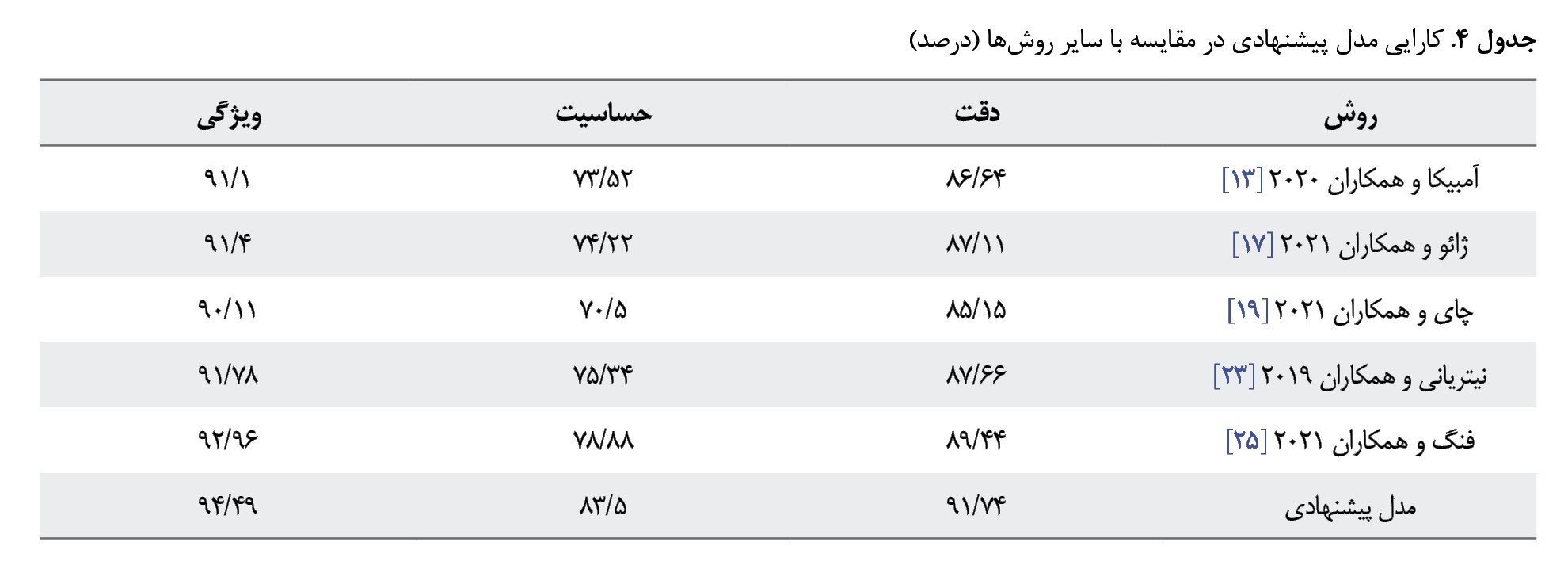
مقایسه کارایی مدل پیشنهادی با روشهای جدید دیگر برای تشخیص و پیشبینی فشار خون بالا روی مجموعه داده موردمطالعه نیز در جدول شماره 4 مشاهده میشود. برای مدل پیشنهادی در هر سه معیار دقت، حساسیت و ویژگی، مقادیر بیشتری نسبت به روشهای موردمقایسه به دست آمده است که در جدول با مقادیر پررنگ نشان داده شده است.
بهمنظور بررسی معنادار بودن میزان بهبود دقت در مدل پیشنهادی ازنظر آماری نسبت به روشهای مقایسهشده، از آزمون آماری تی زوجی با سطح معنیداری 05/0 استفاده شد. این آزمون بین مقادیر دقت مدل پیشنهادی و هریک از روشهای دیگر بهصورت جداگانه انجام شد. مقادیر p بهدستآمده در جدول شماره 5 مشاهده میشود.
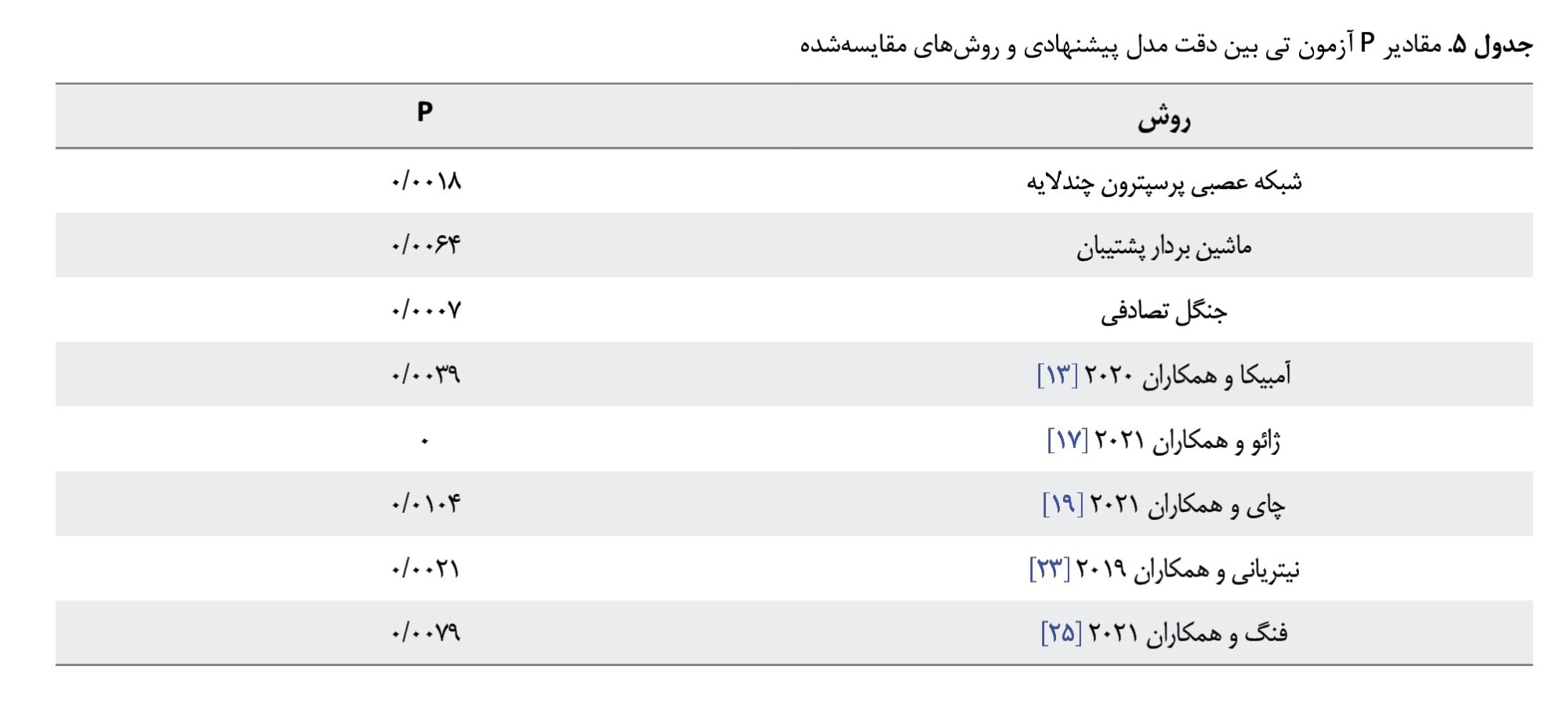
این نتایج نشان میدهند مقادیر p بهدستآمده برای همه روشها کمتر از 0/05 هستند. تصویر شماره 1 بخشی از رابط کاربری برنامه پیادهسازیشده بر مبنای مدل پیشنهادی را نشان میدهد.
بحث
باتوجهبه اهمیت تشخیص و پیشبینی زودهنگام فشار خون بالا در کودکان، در این پژوهش یک مدل توسعهیافته برای پیشبینی و تشخیص فشار خون بالا در کودکان دبستانی با استفاده از روشهای یادگیری ماشین ارائه شد. مدل پیشنهادی در قالب یک برنامه کاربردی قابلاستفاده بر روی گوشی تلفن همراه پیادهسازی شد تا والدین بتوانند نظارت و کنترل مداوم بر فشار خون کودکان خود داشته باشند.
با هدف افزایش دقت در مدل ارائهشده، 3 روش یادگیری مشهور در تشخیص و پیشبینی فشار خون بالا شامل شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی با استفاده از تئوری ترکیب شواهد دمستر شافر با هم ترکیب شدند. مقایسه نتایج بهدستآمده در جدول شماره 3 برای مدل پیشنهادی نسبت به هریک از روشهای یادگیری مشارکتکننده در ساخت مدل نشان میدهد مدل پیشنهادی در هر سه معیار دقت، حساسیت و ویژگی به ترتیب با مقادیر 91/74 درصد، 83/5 درصد و 94/49 درصد برتری دارد. اختلاف این مقادیر در مدل پیشنهادی نسبت به 3 روش شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی قابلتوجه است. این نتیجه، بار دیگر تصدیقکننده این ادعاست که ترکیب روشهای یادگیری میتوانند با غلبه بر محدودیت هریک از روشهای شرکتکننده در ترکیب به بهبود دقت پیشبینی و تشخیص بیماری کمک کنند. مقایسه کارایی 3 روش شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی با هم نشان میدهد که روش جنگل تصادفی نسبت به 2 روش دیگر، عملکرد بهتری داشته و روش ماشین بردار پشتیبان روی مجموعه داده موردمطالعه کمترین کارایی را در تشخیص و پیشبینی فشار خون داشته است.
بررسی نتایج بهدستآمده برای مدل پیشنهادی در مقایسه با سایر روشهای جدید دیگر در جدول شماره 4 نیز برتری مدل پیشنهادی در همه معیارها را نشان میدهد. مدل پیشنهادی و روش ارائهشده توسط آمبیکا و همکاران [13] فشار خون نمونه ورودی را به 4 دسته فشار خون نرمال، پیشفشار خون، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 تقسیم میکنند. سایر روشهای مقایسهشده، نمونهها را به یکی از 2 دسته نرمال و فشار خون بالا دستهبندی میکنند. بعد از مدل پیشنهادی، روش ارائهشده توسط فنگ و همکاران [25] که پیشبینی را براساس ترکیب نتایج خروجی 2 روش یادگیری نزدیکترین k همسایه و تقویت گرادیان سبک بر روی دادههای متوازن انجام میدهد، کارایی بهتری دارد. کارایی روش فیتریانی و همکاران [23] که مبتنی بر ترکیب نتایج خروجی 3 روش یادگیری شبکههای عصبی مصنوعی چندلایه، ماشین درخت تصمیم و ماشین بردار پشتیبان به کمک رگرسیون لجستیک است و کارایی روش ژائو و همکاران [17] که با استفاده از روش جنگل تصادفی عمل پیشبینی را انجام میدهد، به ترتیب پس از روش فنگ و همکاران [25] قرار دارند. روش آمبیکا و همکاران [13] که توسعهیافته روش ماشین بردار پشتیبان است، در مقایسه با نتایج بهدستآمده برای روش ماشین بردار پشتیبان در جدول شماره 3 عملکرد بسیار خوبی داشته است. با وجود این، این روش در مقایسه با روشهای جدید مقایسهشده در جدول شماره 4، بهجز روش چای و همکاران [19]، عملکرد پایینتری داشته است. روش چای و همکاران [19] بهعنوان مدلی توسعهیافته از روش شبکههای عصبی مصنوعی چندلایه نسبت به سایر روشهای جدول شماره 4 عملکرد پایینتری دارد. مقایسه مقادیر 3 معیار دقت، حساسیت و ویژگی برای این روش در جدول شماره 4 با مقادیر بهدستآمده این معیارها برای روش شبکههای عصبی مصنوعی چندلایه در جدول شماره 3 نشان میدهند که روش چای و همکاران [19] بهعنوان مدلی توسعهیافته از شبکههای عصبی مصنوعی چندلایه، با اختلاف ناچیزی از شبکههای عصبی مصنوعی چندلایه برتری دارد. عملکرد نه چندان مطلوب روش چای و همکاران [19] میتواند به این دلیل باشد که این روش عمل پیشبینی را بر روی دادههای نامتوازن انجام میدهد.
نتیجهگیری
باتوجهبه نتایج حاصل از آزمون تی در جدول شماره 5، ازآنجاییکه مقادیر p بهدستآمده کمتر از 0/05 هستند، میتوان نتیجه گرفت اختلاف دقت مدل پیشنهادی در مقایسه با روشهای یادگیری استفادهشده در ترکیب و همچنین سایر روشهای مورد مقایسه، ازنظر آماری معنادار است. بهطور خلاصه نتایج بیانگر این هستند که مدل ترکیبی پیشنهادی، پیشبینی و تشخیص فشار خون بالا در کودکان را بهتر انجام داده و به بهبود دقت و کاهش میزان خطا کمک میکند. در حالت معمولی اندازهگیری فشار خون به تجهیزاتی نیاز دارد که همیشه بهراحتی در دسترس نیست و ممکن است برای برخی از مردم نیز عملی نباشد. برنامه کاربردی پیادهسازیشده بر مبنای مدل پیشنهادی با قابلیت استفاده بر روی گوشی معمولی تلفن همراه، در تشخیص زودهنگام فشار خون بالا در کودکان مفید بوده و به دلیل عدم نیاز به دسترسی به دادههای بالینی و ژنتیکی و همچنین سهولت استفاده از آن میتواند توسط افراد معمولی، ازجمله والدین استفاده شود. این برنامه کاربردی با کاربری آسان، با دریافت اطلاعات اولیه جمعیتشناختی، اطلاعات سبک زندگی و سوابق بیماری خانوادگی و همچنین برخی دادههای معمولی که بهراحتی در کودکان قابلاندازهگیری هستند، میتواند بهعنوان یک ابزار ارزشمند برای تشخیص فشار خون بالا در کودکان، اولین گام در مراقبت از فشار خون بالا باشد و از عوارض و هزینههای ناشی از این بیماری بکاهد. والدین با استفاده از این برنامه کاربردی بهعنوان یک سامانه هشدار اولیه، میتوانند از وضعیت فشار خون کودکان خود مطلع شده و در صورت وجود خطر برای بررسی دقیقتر به پزشک مراجعه کنند. این برنامه کاربردی، علاوه بر مبنایی برای پیشگیری و درمان بهموقع و مناسب، میتواند به تصمیمگیری در تخصیص منابع بهداشتی و سیاست گذاریهای لازم نیز کمک کند. باتوجهبه مطالعات انجامشده، در هیچیک از پژوهشهای انجامشده تاکنون، برنامه کاربردی مشابهی طراحی و پیادهسازی نشده است.
اگرچه رویکرد ترکیبی پیشنهادشده از دقت بهتری در تشخیص و پیشبینی فشار خون بالا برخوردار است، ولی استفاده موازی از چند روش یادگیری ماشین و ترکیب نتایج آنها، باعث افزایش زمان اجرایی و پیچیدگی محاسبات میشود. هرچند در کاربردهایی نظیر پزشکی که با حیات انسانها سروکار دارند، دقت و اعتماد در اولویت است، توصیه میشود در پژوهشهای آینده، ارائه راهکارهایی بهمنظور کاهش زمان اجرایی و پیچیدگی محاسبات در مدل ترکیبی مد نظر باشد. همچنین باتوجهبه اینکه مدل پیشنهادی فقط بر روی مجموعه دادههای کودکان دبستانی یک منطقه جغرافیایی مورد بررسی قرار گرفته است، در پژوهشهای آینده، تعمیم مدل ارائهشده و ارزیابی آن بر روی مجموعه دادههای مربوط به کودکان سایر نواحی و مناطق مفید خواهد بود. ارزیابی برنامه کاربردی پیادهسازیشده و همچنین توسعه آن بهعنوان یک سامانه پایش از راه دور فشار خون، بهطوریکه هشدارها و اعلانهای مناسب را بهصورت خودکار به پزشک و یا مرکز درمانی ثبتشده در برنامه، ارسال کند تا خدمات مراقبتهای بهداشتی و سلامت، بلافاصله و بهموقع به کودکان ارائه شود نیز مورد توجه است.
ملاحظات اخلاقی
پیروی از اصول اخلاق پژوهش
این مطالعه دارای تأییدیه اخلاقی به شماره IR.MUMS.REC.1401.038 از دانشگاه علومزشکی مشهد است.
حامی مالی
این مقاله ازطرف هیچ گونه نهاد یا مؤسسهای حمایت مالی نشده و تمام منابع مالی آن ازطرف نویسندگان تأمین شده است.
مشارکت نویسندگان
مفهومسازی، روششناسی، اعتبارسنجی، تحلیل، تحقیق و بررسی: همه نویسندگان، منابع، نگارش پیشنویس، ویراستاری و نهاییسازی نوشته: حمیدرضا طهماسبی
تعارض منافع
بنابر اظهار نویسندگان این مطالعه تعارض منافع ندارد.
فشار خون بالا در بزرگسالی یک عامل بسیار رایج در افزایش خطر حمله قلبی، بیماریهای قلبیعروقی و مرگومیر است [1-4]. شواهد زیادی وجود دارد که نشان میدهد فشار خون بالا و بیماریهای قلبیعروقی در بزرگسالی از دوران کودکی منشأ میگیرند [5، 6]. امروزه تعداد فزایندهای از کودکان و نوجوانان به دلایلی از قبیل شیوه زندگی، تغذیه، عدم فعالیت فیزیکی، اضافهوزن و چاقی، دچار فشار خون بالا میشوند. بررسی انجامشده در مطالعه [7] افزایش قابلتوجه در ابتلای کودکان و نوجوانان به فشار خون بالا در دو دهه اخیر در جهان را گزارش میکند. در ایران نیز در مطالعه جامعی که انجام شده [8]، شیوع فشار خون در کودکان ایرانی بالا گزارش شده و باتوجهبه افزایش سالبهسال آن، بر نیاز به توجه بیشتر به این عارضه در کودکان تأکید شده است. فشار خون بالا حتی در دوران کودکی خطر ابتلا به تصلب شرایین و بیماریهای قلبیعروقی را افزایش میدهد [5]. فشار خون کودکان نیازمند اقدامات برنامهریزیشده برای به حداقل رساندن افزایش فشار خون در بزرگسالان و بیماریهای قلبیعروقی در آینده است [8].
باتوجهبه پیامدهای درازمدت فشار خون بالای کنترلنشده در کودکان برای سلامتی، شناسایی زودهنگام کودکان پرفشار خون و یا در معرض خطر ابتلا به فشار خون و شروع پیشگیری از فشار خون بالا در اوایل زندگی ضروری است و این موضوع به یکی از مهمترین چالشهای بهداشت عمومی در سراسر جهان تبدیل شده است [3، 7]. فشار خون بالا معمولاً بدون علامت است و باعث میشود شانس تشخیص زودهنگام آن بهشدت کاهش یابد [9]. در سالهای اخیر استفاده از روشهای یادگیری ماشین بهعنوان یک راهکار مفید و مؤثر در پیشبینی و کنترل بیماریها از اهمیت خاصی برخوردار شده است. یادگیری ماشین شاخهای از هوش مصنوعی است که علوم کامپیوتر، آمار و نظریه تصمیم را برای یادگیری و استخراج الگوهای پیچیده از حجم انبوهی از دادهها ترکیب میکند. مطالعات انجامشده در 2 دهه اخیر، سودمند بودن استفاده از یادگیری ماشین برای تشخیص و پیشبینی فشار خون را نشان میدهند. بهطوریکه مورد توجه بسیاری از پژوهشگران قرار گرفته است [2، 4، 10-12]. بهعنوان مثال آمبیکا و همکاران [13] با توسعه روش یادگیری ماشین بردار پشتیبان، یک سیستم پشتیبان تصمیم برای پیشبینی ابتلا به فشار خون بالا از روی اطلاعات سوابق پزشکی و شیوه زندگی افراد با دقت 91/88 درصد پیشنهاد کردند.
ایسلام و همکاران [14] نیز از روشهای یادگیری ماشین درخت تصمیم، جنگل تصادفی، رگرسیون خطی، تقویت گرادیان، تقویت گرادیان شدید و روش آنالیز تشخیص خطی برای پیشبینی فشار خون بالا و همچنین شناسایی عوامل مؤثر بر این عارضه استفاده کردند. ارزیابی آنها نشان داد روشهای رگرسیون خطی، تقویت گرادیان شدید و آنالیز تشخیص خطی با دقتی حدود 90 درصد، بهتر از روشهای جنگل تصادفی و درخت تصمیم بوده و ویژگیهای سن و شاخص توده بدنی، عوامل مؤثر در فشار خون بالا در مجموعه داده موردبررسی بودهاند. در تحقیق مشابه، آنح و همکاران [15] از روشهای درخت تصمیم، بیزن ساده، نزدیکترین k همسایه، شبکههای عصبی مصنوعی، ماشین بردار پشتیبان، جنگل تصادفی، رگرسیون خطی، رأیگیری و تقویت گرادیان شدید برای پیشبینی فشار خون بالا استفاده کردند. یافتههای آنها بیانگر عملکرد بهتر روش جنگل تصادفی نسبت به سایر روشهای مقایسهشده بود.
الکعبی و همکاران [16] با استفاده از 3 روش درخت تصمیم، جنگل تصادفی و رگرسیون لجستیک، مدلی برای پیشبینی فشار خون بالا پیشنهاد کردند. در این مطالعه، روش جنگل تصادفی با دقت پیشبینی 82/1 درصد، کارایی بهتری در تشخیص وجود فشار خون بالا داشت. ژائو و همکاران [17] با استفاده از روش یادگیری جنگل تصادفی روشی برای پیشبینی فشار خون بالا از روی ویژگیهایی که از افراد و بدون نیاز به ابزار تخصصی خاصی به دست میآید، ارائه کردند. دقت این روش حدود 82 درصد بود و ویژگیهای سن، دور کمر، شاخص توده بدنی و سابقه خانوادگی فشار خون را بهعنوان عوامل اصلی فشار خون بالا در مجموعه داده موردنظر شناسایی کرده است.
چای و همکاران [18] روشهای مختلف یادگیری ماشین را برای تشخیص فشار خون بالا در نوجوانان 13 تا 17 ساله بررسی کردند. یافتههای آن ها نشان داد روش یادگیری تقویت گرادیان سبک در مقایسه با سایر روشها برای تشخیص فشار خون بالا عملکرد بهتری داشته است. آنها همچنین در مطالعه دیگری [19] با توسعه روش یادگیری شبکههای عصبی مصنوعی، مدلی با دقت 76 درصد در پیشبینی فشار خون بالا در نوجوانان پیشنهاد کردند. دهقاندار و همکاران [20] از شبکهها عصبی مصنوعی برای تشخیص فشار خون بالا و چاقی در دانشآموزان 7 تا 18 ساله استفاده کردند. این روش، فشار خون سیستولیک را با دقت 74 درصد و فشار خون دیاستولیک را با دقت 79 درصد تشخیص داد.
برخی از مدلهای موفق پیشنهادی برای تشخیص و پیشبینی فشار خون بالا از ترکیب نتایج خروجی چند روش یادگیری مختلف استفاده کردهاند. این رویکرد ترکیبی یک راهکار سودمند برای بهبود دقت دستهبندی است و مطالعات مختلف نشان دادهاند ترکیب روشهای یادگیری در مقایسه با هریک از روشهای یادگیری استفادهشده در ترکیب، دقت بیشتری داشته [21] و نقش مؤثری در افزایش دقت تشخیص فشار خون بالا و عوامل مؤثر بر آن دارد [22، 23]. فیتریانی و همکاران [23] روشی با ترکیب الگوریتمهای یادگیری ماشین بردار پشتیبان، شبکههای عصبی مصنوعی چندلایه و ماشین درخت تصمیم و یک مدل رگرسیون لجستیک برای پیشبینی فشار خون ارائه کردند. این روش برای تشخیص فشار خون در مردان دقتی برابر 85/73 درصد و در زنان دقتی برابر 75/78 درصد داشته است.
کانگائی و همکاران [24] با استفاده از روشهای درخت تصمیم، جنگل تصادفی و رگرسیون خطی یک مدل ترکیبی برای پیشبینی فشار خون بالا پیشنهاد کردند. در این مدل، هریک از 3 روش یادگیری بهصورت مستقل عمل پیشبینی را انجام داده و نتیجه نهایی ازطریق میانگین نتایج آنها به دست میآید. یک مدل ترکیبی نیز توسط فنگ و همکاران [25] پیشنهاد شد که نتایج خروجی 2 روش یادگیری نزدیکترین k همسایه و تقویت گرادیان سبک را برای پیشبینی فشار خون بالا براساس میانگین وزنی آنها ترکیب میکند. ارزیابی آنها نشان داد این مدل دقتی حدود 86 درصد دارد.
باتوجهبه ضرورت تشخیص زودهنگام یا پیشبینی مداوم فشار خون در دوران کودکی برای به حداقل رساندن خطر فشار خون بالا و عوارض آن، هدف این مقاله ارائه مدلی توسعهیافته با استفاده از روشهای یادگیری ماشین برای تشخیص و پیشبینی فشار خون بالا در کودکان دبستانی و پیادهسازی مدل پیشنهادی در قالب یک برنامه کاربردی مبتنی بر تلفن همراه برای استفاده والدین کودکان است. در مدل پیشنهادی، عمل تشخیص و پیشبینی فشار خون بالا با ترکیب نتایج حاصل از 3 روش یادگیری ماشین متداول با استفاده از تئوری ترکیب شواهد دمپستر شافر انجام شد. اغلب روشهای پیشنهادی در مطالعات مرتبط، نمونه ورودی را به یکی از 2 دسته فشار خون نرمال و فشار خون بالا دستهبندی میکنند. درحالیکه در مدل ارائهشده در این مقاله، باتوجهبه دستورالعمل آکادمی پزشکی اطفال آمریکا [26]، نمونههای ورودی به یکی از 4 دسته نرمال، پیش فشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 دستهبندی میشوند. امروزه گوشیهای تلفن همراه به بخشی جداییناپذیر از زندگی اکثر مردم تبدیل شدهاند. تشخیص و پیشبینی فشار خون بالا به کمک گوشی تلفن همراه به دلیل سهولت استفاده برای بسیاری از مردم، میتواند توانایی نظارت بر فشار خون را افزایش دهد. در برنامه کاربردی پیادهسازیشده، والدین میتوانند با ورود اطلاعاتی که بهراحتی از کودکان و بدون نیاز به ابزار تخصصی خاصی قابلدستیابی است بر فشار خون فرزندان خود کنترل و نظارت مداوم داشته باشند.
مواد و روشها
این پژوهش از نوع کاربردیتوسعهای بود که در آن ابتدا مدلی برای پیشبینی فشار خون بالا در کودکان دبستانی با استفاده از روشهای یادگیری ماشین ارائه شد و سپس با استفاده از این مدل پیشنهادی، یک برنامه کاربردی قابلاستفاده در گوشی تلفن همراه برای تشخیص و پیشبینی فشار خون بالا در کودکان طراحی و پیادهسازی شد. نمونه آماری 1287 نفر از دانشآموزان بین 7 تا 13 ساله دبستانهای شهر کاشمر شامل 542 پسر و 745 دختر بودند که مقادیر مربوط به 19 ویژگی مؤثر در فشار خون این دانشآموزان با رضایت کتبی والدین آنها جمعآوری شد. این ویژگیها در جدول شماره 1 مشاهده میشوند. مقادیر ویژگیهای جنسیت، سن، میزان مصرف نمک، سابقه مصرف داروهای مؤثر بر فشار خون، سابقه بیماریهای دیابت، قلبی، کلیوی و سایر بیماریها و سابقه خانوادگی پرفشاری خون ازطریق پرسشنامه تکمیلشده توسط والدین دانشآموزان، به دست آمد. قد هر دانشآموز در حالت کاملاً ایستاده بدون کفش و کلاه، برحسب سانتیمتر و وزن هر دانشآموز بدون کفش و با حداقل لباس ممکن برحسب کیلوگرم، اندازهگیری شد. مقدار اعشاری بهدستآمده برای وزن، به نزدیکترین عدد صحیح قبل و یا بعد آن گرد شد. شاخص توده بدنی بهصورت نسبت وزن برحسب کیلوگرم به مجذور قد برحسب متر مربع برای هر دانشآموز محاسبه شد. نبض نیز با استفاده از کورنومتر برای مدت 1 دقیقه اندازهگیری شد.
فشار خون سیستولیک و دیاستولیک برحسب میلیمتر جیوه، در وضعیت نشسته و پس از استراحت 5 دقیقهای فرد دانشآموز، 2 بار و به فاصله 5 دقیقه با دستگاه فشارسنج عقربهای اندازهگیری شد. میانگین 2 بار اندازهگیری، بهعنوان فشار خون نهایی فرد در نظر گرفته شد. از مقادیر فشار خون سیستولیک و دیاستولیک برای تعیین مقدار ویژگی تشخیص توسط فرد خبره و دستهبندی هر دانشآموز به یکی از 4 دسته فشار خون نرمال، پیش فشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 باتوجهبه دستورالعمل آکادمی پزشکی اطفال آمریکا [26] (جدول شماره 2) استفاده شد و کاربرد دیگری در این پژوهش نداشته است. براساس این دستهبندی، تعداد نمونههای متعلق به هر دسته در ردیف 19 جدول شماره 1 مشاهده میشود.
کیفیت دادهها و آمادهسازی آنها نقش مهمی در افزایش کارایی مدل یادگیری دارند [13]. بنابراین پیشپردازش دادههای جمعآوریشده بهعنوان اولین گام در مدل پیشنهادی مورد توجه قرار گرفته است. در این مرحله، برای جانشینی مقادیر نامشخص از روش میانه/مد [27] استفاده شد. برایناساس، در اطلاعات جمعآوریشده مربوط به 58 دانشآموز، مقدار ویژگی میزان مصرف نمک نامشخص بود که مقدار «مصرف طبیعی» که بیشترین تکرار را در بین مقادیر این ویژگی در مجموعه داده دارد، برای آنها منظور شد. مجموعه داده جمعآوریشده نامتوازن است. بهطوریکه تعداد نمونههای دارای فشار خون نرمال نسبت به سایر نمونهها بسیار بیشتر هستند. مسئله نامتوازن بودن دادهها در اکثر دادههای پزشکی وجود دارد و معمولاً باعث میشود دقت مدل یادگیری تحت تأثیر قرار گرفته و نمونههای متعلق به دسته اقلیت بهعنوان نمونههای دسته اکثریت دستهبندی شوند [23، 28]. برای غلبه بر این مشکل و متوازنسازی دادهها در مدل پیشنهادی از روش معروف SMOTE استفاده شد. در این روش، برای دستههای با تعداد نمونههای کمتر، نمونههای جدیدی در همسایگی نمونههای متعلق به آن دستهها تولید شده و درنتیجه بین تعداد نمونههای متعلق به هریک از دستهها، توازن ایجاد میشود. با متوازنسازی دادههای جمعآوریشده، تعداد نمونههای دستههای پیشفشار خون بالا، فشار خون مرحله 1 و فشار خون مرحله 2 به ترتیب به 1054، 1064 و 1032 نمونه افزایش یافت. پس از متوازنسازی دادهها، با استفاده از روش نرمالسازی متداول حداقل حداکثر، مقادیر همه ویژگیها به مقادیری در بازه 1-0 تبدیل شدند.
پس از پیشپردازش دادهها، ساخت و یادگیری مدل انجام شد. در مدل پیشنهادی بهمنظور افزایش دقت در تشخیص و پیشبینی فشار خون بالا از رویکرد ترکیبی استفاده شد. ابتدا 3 روش یادگیری ماشین متداول استفادهشده در تشخیص و پیشبینی فشار خون بالا [2، 4، 12]، شامل شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی، بهصورت مجزا روی مجموعه دادهها اعمال و عمل پیشبینی انجام شد. بدین منظور از ماژولهای نرمافزار دادهکاوی Weka نسخه 3/7/8 با پارامترهای پیشفرض استفاده شد. سپس نتایج حاصل از 4 روش یادگیری مذکور با استفاده از تئوری ترکیب شواهد دمپستر شافر جهت پیشبینی نهایی با هم ترکیب شدند. ویژگیهای بازیابی صریح عدم قطعیت و قاعده ترکیب شواهد در این تئوری باعث استفاده از آن در مدل پیشنهادی شده است. در تئوری ترکیب شواهد دمپستر شافر، باور مقداری است که برای بیان قطعیت یک گزاره یا رویداد به کار میرود. قاعده ترکیب شواهد در این تئوری، 2 بدنه شواهد مستقل تعریفشده در یک چارچوب مشاهدات را با هم ترکیب کرده و به 1 بدنه شواهد تبدیل میکند [21]. این تئوری، نتایج خروجی روشهای یادگیری را بهعنوان شواهد در نظر گرفته و با رویهمگذاری آنها، یک تابع باور تولید میکند که براساس آن، پیشبینی نهایی انجام میشود. در مدل پیشنهادی، 4 دسته فشار خون نرمال، پیشفشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 بهعنوان چارچوب مشاهدات در نظر گرفته شدند. خروجی روشهای یادگیری بهعنوان شواهد با هم ترکیب شده و براساس مقادیر باور حاصلشده، دسته با بزرگترین مقدار باور بهعنوان دسته نمونه ورودی تعیین میشود. در صورت وجود عدم قطعیت برای پیشبینی فشار خون در نمونه ورودی، این نمونه به هیچ دستهای تعلق نمییابد. روش ترکیبی با زبان برنامهنویسی پایتون پیادهسازی شد.
برای ارزیابی کارایی مدل ارائهشده همانند اغلب مطالعات مشابه [14، 15، 17، 18، 23] از روش اعتبارسنجی متقابل 10 تکه برابر استفاده شده است. معیارهای ارزیابی شامل دقت، حساسیت و ویژگی بوده که بهصورت فرمول شماره 1 محاسبه میشوند.
در این روابط، m بیانگر تعداد دستهها میباشد. TPi (True Positive) تعداد نمونههای متعلق به دسته i است که درست تشخیص و دستهبندی شدهاند.TNi (True Negative) تعداد نمونههای متعلق به سایر دستهها است که در دسته i دستهبندی نشدهاند. FPi (False Positive) تعداد نمونههایی است که به اشتباه در دسته i دستهبندی شدهاند. FNi (False Negative) نیز تعداد نمونههای متعلق به دسته i است که اشتباهی در دسته دیگری دستهبندی شدهاند.
مدل ارائهشده در قالب یک برنامه کاربردی اندرویدی قابلاستفاده بر روی گوشی تلفن همراه، با استفاده از چارچوب ساخت نرمافزار کیوی (Kivy) و زبان برنامهنویسی پایتون پیادهسازی شد. در این برنامه کاربردی، کاربر اطلاعات درخواستشده را وارد کرده و سپس با کلیک بر روی مشاهده نتیجه، نتیجه پیشبینی را در یکی از دستههای نرمال، پیشفشار خون بالا، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 مشاهده میکند.
یافتهها
تعداد نمونههای دستههای پیشفشار خون بالا، فشار خون مرحله 1 و فشار خون مرحله 2 پس از متوازنسازی در مدل پیشنهادی به ترتیب از 62، 121 و 43 به 1054، 1064 و 1032 نمونه افزایش یافت.
جدول شماره 3 نتایج بهدستآمده برای هریک از معیارهای دقت، حساسیت و ویژگی در مدل پیشنهادی و همچنین روشهای یادگیری شرکتکننده در ترکیب شامل شبکه عصبی پرسپترون چندلایه، ماشین بردار پشتیبان و جنگل تصادفی را نشان میدهد. مقادیر پررنگ در این جدول بیانگر بیشترین مقدار در هر معیار هستند. این یافتهها نشان میدهند مقادیر بهدستآمده از هر سه معیار موردمقایسه در مدل پیشنهادی از 3 روش یادگیری استفادهشده در ترکیب، بهطور چشمگیری بیشتر هستند.
مقایسه کارایی مدل پیشنهادی با روشهای جدید دیگر برای تشخیص و پیشبینی فشار خون بالا روی مجموعه داده موردمطالعه نیز در جدول شماره 4 مشاهده میشود. برای مدل پیشنهادی در هر سه معیار دقت، حساسیت و ویژگی، مقادیر بیشتری نسبت به روشهای موردمقایسه به دست آمده است که در جدول با مقادیر پررنگ نشان داده شده است.
بهمنظور بررسی معنادار بودن میزان بهبود دقت در مدل پیشنهادی ازنظر آماری نسبت به روشهای مقایسهشده، از آزمون آماری تی زوجی با سطح معنیداری 05/0 استفاده شد. این آزمون بین مقادیر دقت مدل پیشنهادی و هریک از روشهای دیگر بهصورت جداگانه انجام شد. مقادیر p بهدستآمده در جدول شماره 5 مشاهده میشود.
این نتایج نشان میدهند مقادیر p بهدستآمده برای همه روشها کمتر از 0/05 هستند. تصویر شماره 1 بخشی از رابط کاربری برنامه پیادهسازیشده بر مبنای مدل پیشنهادی را نشان میدهد.
بحث
باتوجهبه اهمیت تشخیص و پیشبینی زودهنگام فشار خون بالا در کودکان، در این پژوهش یک مدل توسعهیافته برای پیشبینی و تشخیص فشار خون بالا در کودکان دبستانی با استفاده از روشهای یادگیری ماشین ارائه شد. مدل پیشنهادی در قالب یک برنامه کاربردی قابلاستفاده بر روی گوشی تلفن همراه پیادهسازی شد تا والدین بتوانند نظارت و کنترل مداوم بر فشار خون کودکان خود داشته باشند.
با هدف افزایش دقت در مدل ارائهشده، 3 روش یادگیری مشهور در تشخیص و پیشبینی فشار خون بالا شامل شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی با استفاده از تئوری ترکیب شواهد دمستر شافر با هم ترکیب شدند. مقایسه نتایج بهدستآمده در جدول شماره 3 برای مدل پیشنهادی نسبت به هریک از روشهای یادگیری مشارکتکننده در ساخت مدل نشان میدهد مدل پیشنهادی در هر سه معیار دقت، حساسیت و ویژگی به ترتیب با مقادیر 91/74 درصد، 83/5 درصد و 94/49 درصد برتری دارد. اختلاف این مقادیر در مدل پیشنهادی نسبت به 3 روش شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی قابلتوجه است. این نتیجه، بار دیگر تصدیقکننده این ادعاست که ترکیب روشهای یادگیری میتوانند با غلبه بر محدودیت هریک از روشهای شرکتکننده در ترکیب به بهبود دقت پیشبینی و تشخیص بیماری کمک کنند. مقایسه کارایی 3 روش شبکههای عصبی مصنوعی چندلایه، ماشین بردار پشتیبان و جنگل تصادفی با هم نشان میدهد که روش جنگل تصادفی نسبت به 2 روش دیگر، عملکرد بهتری داشته و روش ماشین بردار پشتیبان روی مجموعه داده موردمطالعه کمترین کارایی را در تشخیص و پیشبینی فشار خون داشته است.
بررسی نتایج بهدستآمده برای مدل پیشنهادی در مقایسه با سایر روشهای جدید دیگر در جدول شماره 4 نیز برتری مدل پیشنهادی در همه معیارها را نشان میدهد. مدل پیشنهادی و روش ارائهشده توسط آمبیکا و همکاران [13] فشار خون نمونه ورودی را به 4 دسته فشار خون نرمال، پیشفشار خون، فشار خون بالای مرحله 1 و فشار خون بالای مرحله 2 تقسیم میکنند. سایر روشهای مقایسهشده، نمونهها را به یکی از 2 دسته نرمال و فشار خون بالا دستهبندی میکنند. بعد از مدل پیشنهادی، روش ارائهشده توسط فنگ و همکاران [25] که پیشبینی را براساس ترکیب نتایج خروجی 2 روش یادگیری نزدیکترین k همسایه و تقویت گرادیان سبک بر روی دادههای متوازن انجام میدهد، کارایی بهتری دارد. کارایی روش فیتریانی و همکاران [23] که مبتنی بر ترکیب نتایج خروجی 3 روش یادگیری شبکههای عصبی مصنوعی چندلایه، ماشین درخت تصمیم و ماشین بردار پشتیبان به کمک رگرسیون لجستیک است و کارایی روش ژائو و همکاران [17] که با استفاده از روش جنگل تصادفی عمل پیشبینی را انجام میدهد، به ترتیب پس از روش فنگ و همکاران [25] قرار دارند. روش آمبیکا و همکاران [13] که توسعهیافته روش ماشین بردار پشتیبان است، در مقایسه با نتایج بهدستآمده برای روش ماشین بردار پشتیبان در جدول شماره 3 عملکرد بسیار خوبی داشته است. با وجود این، این روش در مقایسه با روشهای جدید مقایسهشده در جدول شماره 4، بهجز روش چای و همکاران [19]، عملکرد پایینتری داشته است. روش چای و همکاران [19] بهعنوان مدلی توسعهیافته از روش شبکههای عصبی مصنوعی چندلایه نسبت به سایر روشهای جدول شماره 4 عملکرد پایینتری دارد. مقایسه مقادیر 3 معیار دقت، حساسیت و ویژگی برای این روش در جدول شماره 4 با مقادیر بهدستآمده این معیارها برای روش شبکههای عصبی مصنوعی چندلایه در جدول شماره 3 نشان میدهند که روش چای و همکاران [19] بهعنوان مدلی توسعهیافته از شبکههای عصبی مصنوعی چندلایه، با اختلاف ناچیزی از شبکههای عصبی مصنوعی چندلایه برتری دارد. عملکرد نه چندان مطلوب روش چای و همکاران [19] میتواند به این دلیل باشد که این روش عمل پیشبینی را بر روی دادههای نامتوازن انجام میدهد.
نتیجهگیری
باتوجهبه نتایج حاصل از آزمون تی در جدول شماره 5، ازآنجاییکه مقادیر p بهدستآمده کمتر از 0/05 هستند، میتوان نتیجه گرفت اختلاف دقت مدل پیشنهادی در مقایسه با روشهای یادگیری استفادهشده در ترکیب و همچنین سایر روشهای مورد مقایسه، ازنظر آماری معنادار است. بهطور خلاصه نتایج بیانگر این هستند که مدل ترکیبی پیشنهادی، پیشبینی و تشخیص فشار خون بالا در کودکان را بهتر انجام داده و به بهبود دقت و کاهش میزان خطا کمک میکند. در حالت معمولی اندازهگیری فشار خون به تجهیزاتی نیاز دارد که همیشه بهراحتی در دسترس نیست و ممکن است برای برخی از مردم نیز عملی نباشد. برنامه کاربردی پیادهسازیشده بر مبنای مدل پیشنهادی با قابلیت استفاده بر روی گوشی معمولی تلفن همراه، در تشخیص زودهنگام فشار خون بالا در کودکان مفید بوده و به دلیل عدم نیاز به دسترسی به دادههای بالینی و ژنتیکی و همچنین سهولت استفاده از آن میتواند توسط افراد معمولی، ازجمله والدین استفاده شود. این برنامه کاربردی با کاربری آسان، با دریافت اطلاعات اولیه جمعیتشناختی، اطلاعات سبک زندگی و سوابق بیماری خانوادگی و همچنین برخی دادههای معمولی که بهراحتی در کودکان قابلاندازهگیری هستند، میتواند بهعنوان یک ابزار ارزشمند برای تشخیص فشار خون بالا در کودکان، اولین گام در مراقبت از فشار خون بالا باشد و از عوارض و هزینههای ناشی از این بیماری بکاهد. والدین با استفاده از این برنامه کاربردی بهعنوان یک سامانه هشدار اولیه، میتوانند از وضعیت فشار خون کودکان خود مطلع شده و در صورت وجود خطر برای بررسی دقیقتر به پزشک مراجعه کنند. این برنامه کاربردی، علاوه بر مبنایی برای پیشگیری و درمان بهموقع و مناسب، میتواند به تصمیمگیری در تخصیص منابع بهداشتی و سیاست گذاریهای لازم نیز کمک کند. باتوجهبه مطالعات انجامشده، در هیچیک از پژوهشهای انجامشده تاکنون، برنامه کاربردی مشابهی طراحی و پیادهسازی نشده است.
اگرچه رویکرد ترکیبی پیشنهادشده از دقت بهتری در تشخیص و پیشبینی فشار خون بالا برخوردار است، ولی استفاده موازی از چند روش یادگیری ماشین و ترکیب نتایج آنها، باعث افزایش زمان اجرایی و پیچیدگی محاسبات میشود. هرچند در کاربردهایی نظیر پزشکی که با حیات انسانها سروکار دارند، دقت و اعتماد در اولویت است، توصیه میشود در پژوهشهای آینده، ارائه راهکارهایی بهمنظور کاهش زمان اجرایی و پیچیدگی محاسبات در مدل ترکیبی مد نظر باشد. همچنین باتوجهبه اینکه مدل پیشنهادی فقط بر روی مجموعه دادههای کودکان دبستانی یک منطقه جغرافیایی مورد بررسی قرار گرفته است، در پژوهشهای آینده، تعمیم مدل ارائهشده و ارزیابی آن بر روی مجموعه دادههای مربوط به کودکان سایر نواحی و مناطق مفید خواهد بود. ارزیابی برنامه کاربردی پیادهسازیشده و همچنین توسعه آن بهعنوان یک سامانه پایش از راه دور فشار خون، بهطوریکه هشدارها و اعلانهای مناسب را بهصورت خودکار به پزشک و یا مرکز درمانی ثبتشده در برنامه، ارسال کند تا خدمات مراقبتهای بهداشتی و سلامت، بلافاصله و بهموقع به کودکان ارائه شود نیز مورد توجه است.
ملاحظات اخلاقی
پیروی از اصول اخلاق پژوهش
این مطالعه دارای تأییدیه اخلاقی به شماره IR.MUMS.REC.1401.038 از دانشگاه علومزشکی مشهد است.
حامی مالی
این مقاله ازطرف هیچ گونه نهاد یا مؤسسهای حمایت مالی نشده و تمام منابع مالی آن ازطرف نویسندگان تأمین شده است.
مشارکت نویسندگان
مفهومسازی، روششناسی، اعتبارسنجی، تحلیل، تحقیق و بررسی: همه نویسندگان، منابع، نگارش پیشنویس، ویراستاری و نهاییسازی نوشته: حمیدرضا طهماسبی
تعارض منافع
بنابر اظهار نویسندگان این مطالعه تعارض منافع ندارد.
References
- Nematollahi MA, Jahangiri S, Asadollahi A, Salimi M, Dehghan A, Mashayekh M, et al. Body composition predicts hypertension using machine learning methods: A cohort study. Sci Rep. 2023; 13(1):6885. [DOI:10.1038/s41598-023-34127-6] [PMID]
- Chowdhury MZI, Naeem I, Quan H, Leung AA, Sikdar KC, O'Beirne M, et al. Prediction of hypertension using traditional regression and machine learning models: A systematic review and meta-analysis. Plos One. 2022; 17(4):e0266334. [DOI:10.1371/journal.pone.0266334] [PMID]
- Tozo TAA, Gisi ML, Brand C, Moreira CMM, Pereira BO, Leite N. Family history of arterial hypertension and central adiposity: Impact on blood pressure in schoolchildren. BMC Pediatr. 2022; 22(1):497. [DOI:10.1186/s12887-022-03551-4] [PMID]
- Martinez-R’ios E, Montesinos L, Alfaro-Ponce M, Pecchia L. A review of machine learning in hypertension detection and blood pressure estimation based on clinical and physiological data. Biomed Signal Process Control. 2021; 68:102813. [DOI:10.1016/j.bspc.2021.102813]
- Hamoen M, de Kroon MLA, Welten M, Raat H, Twisk JWR, Heymans MW, et al. Childhood prediction models for hypertension later in life: A systematic review.J Hypertens. 2019; 37(5):865-77. [DOI:10.1097/HJH.0000000000001970] [PMID]
- Hardy ST, Urbina EM. Blood pressure in childhood and adolescence. Am J Hypertens. 2021; 34(3):242-9. [DOI:10.1093/ajh/hpab004]
- Song P, Zhang Y, Yu J, Zha M, Zhu Y, Rahimi K, et al. Global prevalence of hypertension in children: A systematic review and meta-analysis. JAMA Pediatr. 2019; 173(12):1154-63. [DOI:10.1001/jamapediatrics.2019.3310] [PMID]
- Akbari M, Moosazadeh M, Ghahramani S, Tabrizi R, Kolahdooz F, Asemi Z, et al. High prevalence of hypertension among Iranian children and adolescents: A systematic review and meta-analysis. J Hypertens. 2017; 35(6):1155-63. [DOI:10.1097/HJH.0000000000001261] [PMID]
- Frey L, Menon C, Elgendi M. Blood pressure measurement using only a smartphone. NPJ Digit Med. 2022; 5(1):86. [DOI:10.1038/s41746-022-00629-2] [PMID]
- Visco V, Izzo C, Mancusi C, Rispoli A, Tedeschi M, Virtuoso N, et al. Artificial intelligence in hypertension management: An ace up your sleeve. J Cardiovasc Dev Dis. 2023; 10(2):74. [DOI:10.3390/jcdd10020074] [PMID]
- Cai A, Zhu Y, Clarkson SA, Feng Y. The use of machine learning for the care of hypertension and heart failure. JACC Asia. 2021; 1(2):162-72.[DOI:10.1016/j.jacasi.2021.07.005] [PMID]
- Silva GFS, Fagundes TP, Teixeira BC, Chiavegatto Filho ADP. Machine Learning for hypertension prediction: A systematic review. Curr Hypertens Rep. 2022; 24(11):523-33. [DOI:10.1007/s11906-022-01212-6] [PMID]
- Ambika M, Raghuraman G, SaiRamesh L. Enhanced decision support system to predict and prevent hypertension using computational intelligence techniques. Soft Comput. 2020; 24(17):13293-304. [Link]
- Islam SMS, Talukder A, Awal MA, Siddiqui MMU, Ahamad MM, Ahammed B, et al. Machine learning approaches for predicting hypertension and its associated factors using population-level data from three South Asian Countries. Front Cardiovasc Med. 2022; 9:839379. [DOI:10.3389/fcvm.2022.839379] [PMID]
- Oanh TT, Tung NT. Predicting hypertension based on machine learning methods: A case study in Northwest Vietnam. Mobile Netw Appl. 2022; 27:2013–23. [DOI:10.1007/s11036-022-01984-w]
- AlKaabi LA, Ahmed LS, Al Attiyah MF, Abdel-Rahman ME. Predicting hypertension using machine learning: Findings from Qatar Biobank Study. Plos One. 2020; 15(10):e0240370. [DOI:10.1371/journal.pone.0240370] [PMID]
- Zhao H, Zhang X, Xu Y, Gao L, Ma Z, Sun Y, et al. Predicting the risk of hypertension based on several easy-to-collect risk factors: A machine learning method. Front Public Health. 2021; 9:619429. [DOI:10.3389/fpubh.2021.619429] [PMID]
- Chai SS, Goh KL, Cheah WL, Chang YHR, Ng GW. Hypertension prediction in adolescents using anthropometric measurements: Do machine learning models perform equally well? Appl Sci. 2022; 12(3):1600. [DOI:10.3390/app12031600]
- Chai SS, Cheah WL, Goh KL, Chang YHR, Sim KY, Chin KO. A multilayer perceptron neural network model to classify hypertension in adolescents using anthropometric measurements: A cross-sectional study in Sarawak, Malaysia. Comput Math Methods Med. 2021; 2021:2794888.[DOI:10.1155/2021/2794888] [PMID]
- Dehghandar M, Hassani Bafrani A, Dadkhah M, Qorbani M, Kelishadi R. [Diagnosis of obesity and hypertension in Isfahani students using artificial neural network (Persian)]. J Health Biomed Inf. 2021; 8 (1):12-23. [Link]
- Tahmasbi H, Jalali M, Shakeri H. [An expert system for heart disease diagnosis based on evidence combination in data mining (Persian)]. J Health Biomed Inform. 2017; 3(4):251-8. [Link]
- Ren L, Zhang H, Seklouli AS, Wang T, Bouras A. Stacking-based multi-objective ensemble framework for prediction of hypertension. Expert Syst Appl. 2023; 215:119351. [DOI:10.1016/j.eswa.2022.119351]
- Fitriyani NL, Syafrudin M, Alfian G, Rhee J. Development of disease prediction model based on ensemble learning approach for diabetes and hypertension. IEEE Access. 2019; 7:144777-89. [DOI:10.1109/ACCESS.2019.2945129]
- Kanegae H, Suzuki K, Fukatani K, Ito T, Harada N, Kario K. Highly precise risk prediction model for new-onset hypertension using artificial intelligence techniques. J Clin Hypertens. 2020; 22(3):445-50. [DOI:10.1111/jch.13759] [PMID]
- Fang M, Chen Y, Xue R, Wang H, Chakraborty N, Su T, et al. A hybrid machine learning approach for hypertension risk prediction. Neural Comput Appl. 2021; 35:14487–97. [DOI:10.1007/s00521-021-06060-0]
- Rao G. Diagnosis, epidemiology, and management of hypertension in children. Pediatrics. 2016; 138(2):e20153616. [DOI:10.1542/peds.2015-3616] [PMID]
- Tahmasbi H, Amoozgar M, Adine H. [Replacement of missing values and its effect on the classification accuracy in medical data mining (Persian)]. J Health Biomed Inf. 2015; 2(1):24-32. [Link]
- Wang YC, Cheng CH. A multiple combined method for rebalancing medical data with class imbalances. Comput Biol Med. 2021; 134:104527. [DOI:10.1016/j.compbiomed.2021.104527] [PMID]
ارسال پیام به نویسنده مسئول
| بازنشر اطلاعات | |
 |
این مقاله تحت شرایط Creative Commons Attribution-NonCommercial 4.0 International License قابل بازنشر است. |
