

دوره 8، شماره 2 - ( تابستان 1401 )
جلد 8 شماره 2 صفحات 139-126 |
برگشت به فهرست نسخه ها



![]()
![]()
![]()
Download citation:
BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:



BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:
Hosseinpoor M. Predicting Gestational Diabetes Using an Intelligent Algorithm Based on Artificial Neural Network. JMIS 2022; 8 (2) :126-139
URL: http://jmis.hums.ac.ir/article-1-335-fa.html
URL: http://jmis.hums.ac.ir/article-1-335-fa.html
حسین پور محمدجواد. پیشبینی دیابت بارداری با استفاده از یک الگوریتم هوشمند مبتنی بر شبکه عصبی. اطلاعرسانی پزشکی نوین. 1401; 8 (2) :126-139



دانشکده مهندسی کامپیوتر، واحد استهبان، دانشگاه آزاد اسلامی، استهبان، ایران.
متن کامل [PDF 4876 kb]
(675 دریافت)
| چکیده (HTML) (1260 مشاهده)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

References
متن کامل: (878 مشاهده)
مقدمه
تشخیص بیماریها یک فرایند بسیار سخت و پیچیده برای افراد خبره در علوم پزشکی محسوب میشود، بنابراین لزوم استفاده از روشهای مناسب دادهکاوی جهت اتخاذ تشخیص صحیح در مسائل پزشکی ضروری به نظرمیرسد [1]. درنتیجه استفاده از الگوریتمها و تکنیکهای دادهکاوی میتواند الگوها و نتایجی را برای محققین فراهم کند که عوامل ابتلا به بیماریهای مختلف را نشان دهد و براساس آن نتایج، پزشکان و دستاندرکاران علوم پزشکی در پیشگیری آن بیماری اقدام کنند [2]. استخراج دانش از میان حجم انبوه دادهها با استفاده از فرایند دادهکاوی میتواند به شناسایی قوانین حاکم بر بیماریها منجر شده و اطلاعات ارزشمندی را بهمنظور شناسایی علل بیماریها، تشخیص، پیشبینی و درمان بیماریها با توجه به عوامل محیطی در اختیار متخصصان حوزه سلامت قرار دهد و این مسئله به معنای طول عمر و ایجاد آرامش برای افراد جامعه است [3]. بنابراین ضرورت وجود روشی مناسب جهت تشخیص بیماری حس میشود. در این مقاله به این مهم پرداخته شده و بیماری مورد هدف آن بیماری دیابت است [4].
یکی از مشکلات شایع دوران بارداری که در بین زنان باردار مشاهده میشود دیابت بارداری است [5]. پزشکان با تکیه بر تجربیات و دانستههای خود، آزمایشات پیچیده و وقتگیر به بیماری دیابت بارداری پی میبردند [6] با وجود این خطاهای انسانی اجتنابناپذیر است [7]، در این پژوهش سعی شده است با استفاده از یک الگوریتم هوشمند مبتنی بر شبکههای عصبی، روشی را ایجاد کنیم که به بهترین حالت شناسایی و تشخیص زودهنگام دیابت بارداری را انجام دهد. استفاده از الگوریتمهای هوشمند میتواند الگوها و نتایجی را برای محققین فراهم آورد که عوامل ابتلا به بیماری دیابت بارداری را بهسرعت تشخیص دهند [8, 9]. استفاده از الگوریتم هوشمند میتواند بهترین روشهای درمانی و کمهزینهترین روش ها را شناسایی کند [10, 11] و این امر موجب کاهش در هزینههای درمانی میشود [12] در سالهای گذشته پژوهشهای زیادی در این زمینه صورت گرفته است. در ادامه به چندین مورد از آنها اشاره میشود.
محمدی و همکاران، بیماریهای مرتبط با چشم را در دیابت بررسی کردند. این بیماری آثار بدی روی چشمها، سیستم عصبی و سایر اعضای بدن دارد. رتینوپاتی دیابتی عارضهای ناشی از دیابت است که به دلیل تغییرات ایجادشده در عروق خونی شبکیه رخ میدهد. اگزودیتها علامت اصلی از ریتینوپاتی دیابتی هستند. تشخیص زودهنگام میتواند بهطور چشمگیری کوری را کاهش دهد. روش اتوماتیک تشخیص اگزودیت با کنتراست پایین تصاویر دیجیتال و روش خوشهبندی فازی برای بیماران دیابتی با مردمک چشم غیرمستمع، پیشنهاد شده است. پیشپردازش افزایش کنتراست قبل از 4 ویژگی به نام شدت، شدت خطای استاندارد، رنگ و یک تعداد از پیکسلهای لبه، پیادهسازی شده است. پارامترهای تقسیمبندی ضخیم با استفاده از روش خوشهبندی فازی استخراج شدهاند [13]
زاهدیفرد و همکاران، با استفاده از دادهکاوی و تمرکز بر روی دادههای مربوط به افراد دیابتی ثبتشده در طی سالهای 1384 تا 1388 از بیمارستان 17 شهریور واقع در برازجان مرکز شهرستان دشتستان استان بوشهر، و با توجه به متغیرهای پراهمیت 15 متغیر از میان 60 متغیر مرتبط با دیابت افراد دیابتی را در خوشههای مختلف قرار داده و براساس تفسیرهای هر خوشه الگوهایی برای افراد دیابتی استخراج کردند [14].
همچنین میرشریف و همکاران، در سال 1396، به دنبال پیشبینی ریسک و هشدار بهموقع در ابتلا به دیابت بارداری به مادر بودهاند، تا در اوایل بارداری از ابتلا جلوگیری به عمل آید. این پژوهش که بهصورت کاربردیپیمایشی انجام شد و از 2 رویکرد شبکه عصبی و درخت تصمیم در دادهکاوی بهمنظور تجزیهوتحلیل آزمایشی دادهها و پیشبینی استفاده شد [15].
زیبا خوشناموند و همکارانش، پژوهشی با عنوان «تشخیص دیابت به کمک الگوریتم بهینهسازی امواج آب و مقایسه آن با الگوریتمهای یادگیری ماشین» انجام دادند. در این پژوهش یک روش برای تشخیص بیماری دیابت به کمک شبکه عصبی مصنوعی با استفاده از الگوریتم فراابتکاری بهینهسازی امواج آب ارائه شد. اطلاعات بهدستآمده از این پژوهش نشان میدهد که الگوریتم بهینهسازی امواج آب با دقت بیشتری نسبت به ابزارهای دادهکاوی بیماری دیابت را تشخیص میدهد [16].
در تمامی پژوهشهای انجامشده، سیستمهای تشخیص و پیشبینی، قادر به شناسایی بیمار با استفاده از راهکارهای با نظارت هستند. اما در پژوهش پیشِرو، قصد بر این است که یک رویکرد هوشمند و بدون نظارت، مبتنی بر تکنیکهای شبکه عصبیمصنوعی و الگوریتم ژنتیک جهت تشخیص بیماری دیابت بارداری ارائه شود. سیستم پیشنهادی به دنبال بهبود فرایند تشخیص افراد بیمار از بیمار سالم است. همچنین در سیستم پیشنهادی نیز همانند رویکردهای ارائهشده در قبل مسئله دقت تشخیص و پیشبینی نیز ملاک ارزیابی است و در اینجا سعی شده است سیستمی ارائه شود که با دقت بالایی بتواند بیماری دیابت بارداری را پیشبینی کند.
مواد و روشها
پژوهش حاضر از نوع کاربردی توصیفی است که در سال 1399 انجام شده است. روش پیشنهادی در این پژوهش، یک رویکرد یادگیری بدون نظارت جهت تشخیص دیابت بارداری در افراد مبتلا به این بیماری است. الگوریتم موردنظر، حاصل از آمیختگی الگوریتم ژنتیک و شبکه عصبیمصنوعی است. در اینجا ابتدا عملیات خوشهبندی بدون نظارت جهت ایجاد 2 خوشه افراد سالم و بیمار با استفاده از الگوریتم ژنتیک بر روی مجموعه داده ورودی انجام میگیرد. درنهایت پس از انجام 100 مرتبه اجرا بهترین افراز که حاوی بهینهترین خوشهها به دست میآید. بعد از این مرحله، خروجی الگوریتم ژنتیک جهت انجام عملیات آموزش بهعنوان ورودی شبکه عصبیمصنوعی در نظر گرفته میشود. شبکه عصبی موردنظر، یک شبکه عصبی پیشخور با 20 لایه پنهان است.
پس از طراحی شبکه عصبی پیشخور، مجموعه داده ورودی و خوشههای بهدستآمده از الگوریتم ژنتیک، که نشاندهنده برچسبهای مجموعه داده است، بهعنوان ورودی جهت عملیات یادگیری در نظر گرفته میشود. در اینجا 75 درصد مجموعه داده بهعنوان مجموعه داده آموزش و 25 درصد هم بهعنوان مجموعه داده تست در نظر گرفته شده است. تصویر شماره 1 شبهکد الگوریتم پیشنهادی را نشان میدهد.
تشخیص بیماریها یک فرایند بسیار سخت و پیچیده برای افراد خبره در علوم پزشکی محسوب میشود، بنابراین لزوم استفاده از روشهای مناسب دادهکاوی جهت اتخاذ تشخیص صحیح در مسائل پزشکی ضروری به نظرمیرسد [1]. درنتیجه استفاده از الگوریتمها و تکنیکهای دادهکاوی میتواند الگوها و نتایجی را برای محققین فراهم کند که عوامل ابتلا به بیماریهای مختلف را نشان دهد و براساس آن نتایج، پزشکان و دستاندرکاران علوم پزشکی در پیشگیری آن بیماری اقدام کنند [2]. استخراج دانش از میان حجم انبوه دادهها با استفاده از فرایند دادهکاوی میتواند به شناسایی قوانین حاکم بر بیماریها منجر شده و اطلاعات ارزشمندی را بهمنظور شناسایی علل بیماریها، تشخیص، پیشبینی و درمان بیماریها با توجه به عوامل محیطی در اختیار متخصصان حوزه سلامت قرار دهد و این مسئله به معنای طول عمر و ایجاد آرامش برای افراد جامعه است [3]. بنابراین ضرورت وجود روشی مناسب جهت تشخیص بیماری حس میشود. در این مقاله به این مهم پرداخته شده و بیماری مورد هدف آن بیماری دیابت است [4].
یکی از مشکلات شایع دوران بارداری که در بین زنان باردار مشاهده میشود دیابت بارداری است [5]. پزشکان با تکیه بر تجربیات و دانستههای خود، آزمایشات پیچیده و وقتگیر به بیماری دیابت بارداری پی میبردند [6] با وجود این خطاهای انسانی اجتنابناپذیر است [7]، در این پژوهش سعی شده است با استفاده از یک الگوریتم هوشمند مبتنی بر شبکههای عصبی، روشی را ایجاد کنیم که به بهترین حالت شناسایی و تشخیص زودهنگام دیابت بارداری را انجام دهد. استفاده از الگوریتمهای هوشمند میتواند الگوها و نتایجی را برای محققین فراهم آورد که عوامل ابتلا به بیماری دیابت بارداری را بهسرعت تشخیص دهند [8, 9]. استفاده از الگوریتم هوشمند میتواند بهترین روشهای درمانی و کمهزینهترین روش ها را شناسایی کند [10, 11] و این امر موجب کاهش در هزینههای درمانی میشود [12] در سالهای گذشته پژوهشهای زیادی در این زمینه صورت گرفته است. در ادامه به چندین مورد از آنها اشاره میشود.
محمدی و همکاران، بیماریهای مرتبط با چشم را در دیابت بررسی کردند. این بیماری آثار بدی روی چشمها، سیستم عصبی و سایر اعضای بدن دارد. رتینوپاتی دیابتی عارضهای ناشی از دیابت است که به دلیل تغییرات ایجادشده در عروق خونی شبکیه رخ میدهد. اگزودیتها علامت اصلی از ریتینوپاتی دیابتی هستند. تشخیص زودهنگام میتواند بهطور چشمگیری کوری را کاهش دهد. روش اتوماتیک تشخیص اگزودیت با کنتراست پایین تصاویر دیجیتال و روش خوشهبندی فازی برای بیماران دیابتی با مردمک چشم غیرمستمع، پیشنهاد شده است. پیشپردازش افزایش کنتراست قبل از 4 ویژگی به نام شدت، شدت خطای استاندارد، رنگ و یک تعداد از پیکسلهای لبه، پیادهسازی شده است. پارامترهای تقسیمبندی ضخیم با استفاده از روش خوشهبندی فازی استخراج شدهاند [13]
زاهدیفرد و همکاران، با استفاده از دادهکاوی و تمرکز بر روی دادههای مربوط به افراد دیابتی ثبتشده در طی سالهای 1384 تا 1388 از بیمارستان 17 شهریور واقع در برازجان مرکز شهرستان دشتستان استان بوشهر، و با توجه به متغیرهای پراهمیت 15 متغیر از میان 60 متغیر مرتبط با دیابت افراد دیابتی را در خوشههای مختلف قرار داده و براساس تفسیرهای هر خوشه الگوهایی برای افراد دیابتی استخراج کردند [14].
همچنین میرشریف و همکاران، در سال 1396، به دنبال پیشبینی ریسک و هشدار بهموقع در ابتلا به دیابت بارداری به مادر بودهاند، تا در اوایل بارداری از ابتلا جلوگیری به عمل آید. این پژوهش که بهصورت کاربردیپیمایشی انجام شد و از 2 رویکرد شبکه عصبی و درخت تصمیم در دادهکاوی بهمنظور تجزیهوتحلیل آزمایشی دادهها و پیشبینی استفاده شد [15].
زیبا خوشناموند و همکارانش، پژوهشی با عنوان «تشخیص دیابت به کمک الگوریتم بهینهسازی امواج آب و مقایسه آن با الگوریتمهای یادگیری ماشین» انجام دادند. در این پژوهش یک روش برای تشخیص بیماری دیابت به کمک شبکه عصبی مصنوعی با استفاده از الگوریتم فراابتکاری بهینهسازی امواج آب ارائه شد. اطلاعات بهدستآمده از این پژوهش نشان میدهد که الگوریتم بهینهسازی امواج آب با دقت بیشتری نسبت به ابزارهای دادهکاوی بیماری دیابت را تشخیص میدهد [16].
در تمامی پژوهشهای انجامشده، سیستمهای تشخیص و پیشبینی، قادر به شناسایی بیمار با استفاده از راهکارهای با نظارت هستند. اما در پژوهش پیشِرو، قصد بر این است که یک رویکرد هوشمند و بدون نظارت، مبتنی بر تکنیکهای شبکه عصبیمصنوعی و الگوریتم ژنتیک جهت تشخیص بیماری دیابت بارداری ارائه شود. سیستم پیشنهادی به دنبال بهبود فرایند تشخیص افراد بیمار از بیمار سالم است. همچنین در سیستم پیشنهادی نیز همانند رویکردهای ارائهشده در قبل مسئله دقت تشخیص و پیشبینی نیز ملاک ارزیابی است و در اینجا سعی شده است سیستمی ارائه شود که با دقت بالایی بتواند بیماری دیابت بارداری را پیشبینی کند.
مواد و روشها
پژوهش حاضر از نوع کاربردی توصیفی است که در سال 1399 انجام شده است. روش پیشنهادی در این پژوهش، یک رویکرد یادگیری بدون نظارت جهت تشخیص دیابت بارداری در افراد مبتلا به این بیماری است. الگوریتم موردنظر، حاصل از آمیختگی الگوریتم ژنتیک و شبکه عصبیمصنوعی است. در اینجا ابتدا عملیات خوشهبندی بدون نظارت جهت ایجاد 2 خوشه افراد سالم و بیمار با استفاده از الگوریتم ژنتیک بر روی مجموعه داده ورودی انجام میگیرد. درنهایت پس از انجام 100 مرتبه اجرا بهترین افراز که حاوی بهینهترین خوشهها به دست میآید. بعد از این مرحله، خروجی الگوریتم ژنتیک جهت انجام عملیات آموزش بهعنوان ورودی شبکه عصبیمصنوعی در نظر گرفته میشود. شبکه عصبی موردنظر، یک شبکه عصبی پیشخور با 20 لایه پنهان است.
پس از طراحی شبکه عصبی پیشخور، مجموعه داده ورودی و خوشههای بهدستآمده از الگوریتم ژنتیک، که نشاندهنده برچسبهای مجموعه داده است، بهعنوان ورودی جهت عملیات یادگیری در نظر گرفته میشود. در اینجا 75 درصد مجموعه داده بهعنوان مجموعه داده آموزش و 25 درصد هم بهعنوان مجموعه داده تست در نظر گرفته شده است. تصویر شماره 1 شبهکد الگوریتم پیشنهادی را نشان میدهد.
مجموعه داده مورداستفاده
در این مقاله، از مجموعه داده میرشریف و همکاران استفاده شده است [15]. این مجموعه داده مربوط به بیش از صد پرونده بیماران از سال 1390 تا 1393 در تحقیقی میدانی و نمونهگیری هدفمند از کلینیک پزشکی تخصصی زنان در تهران مورد بررسی قرار گرفت که از میان آنها 105 مورد دارای اطلاعات کامل از ابتدا تا انتهای بارداری بودند (80 نفر انسان سالم و 25 نفر انسان بیمار).
محیط شبیهسازی
در این مقاله، برای بررسی سیستم پیشنهادی و ارائه نتایج آن، پیادهسازی رویکرد پیشنهادشده به کمک زبانهایبرنامهنویسی انجام شده است. به این منظور، الگوریتم پیشنهادشده در محیط متلب نسخه R2016a پیادهسازی شده است. زبان برنامهنویسی متلب یکی از زبانهای مفسری است که بهطور گستردهای در رشتههای مهندسی استفادهمیشود. این محیط شبیهسازی شهرت خود را از قابلیت استفاده آسان خود به دست آورده است. آزمایشات در سیستمی با پردازنده INTEL CELERON D800 1.50 GHz و حافظهی داخلی 2 گیگابایت مورد تست و ارزیابی قرار گرفته است.
پارامترها
در الگوریتم پیشنهادی مطابق جدول شماره 1، تعداد تکرار 100 مرتبه، تعداد جمعیت اولیه 100 عدد، درصد عملیات تقاطع 7 و درصد عملیات جهش 3 در نظر گرفته شده است.
.jpg)
همچنین این الگوریتم با اجرای یک چرخ رولت عضوهای جمعیت را جهت عملیات تقاطع و جهش انتخاب میکند. پس از اجرای عملیاتهای تقاطع و جهش، فرزندهای بهدستآمده از این عملیاتها با استفاده از تابع ارزیابی بررسی میشوند. سپس این فرزندان با جمعیت قبلی ادغام شده و 100 فرد از این جمعیت که دارای مقدار ارزیابی بهتری هستند بهعنوان جمعیت جدید انتخاب میشوند. پس از صد تکرار فردی در جمعیت که دارای بهترین مقدار ارزیابی است بهعنوان بهترین فرد شناخته شده و پارتشین بهدستآمده از آن بهعنوان جواب مسئله در نظر گرفته میشود که این پارتیشن شامل خوشههایی از مجموعه داده ورودی است. سپس برچسبهای خوشههای بهدستآمده و مجموعه داده بهعنوان ورودی جهت عملیات یادگیری وارد شبکه عصبی پیشخور میشود. در شبکه عصبی طراحیشده، تعداد لایههای پنهان 20، نوع تابع تبدیل تابع سیگموئیدی و نرخ یادگیری و تست نیز به ترتیب 75 و 25 درصد تنظیم شده است.
یافتهها
نحوه انجام کار روش پیشنهادی
در این بخش، نحوه انجام کار روش پیشنهادی در محیط متلب توضیح داده میشود. در اینجا ابتدا عملیات خوشهبندی بدون نظارت جهت ایجاد 2 خوشه افراد سالم و بیمار با استفاده از الگوریتم ژنتیک بر روی مجموعه داده ورودی انجام میگیرد. سپس مجموعه داده ورودی و خروجی الگوریتم ژنتیک جهت انجام عملیات آموزش بهعنوان ورودی شبکه عصبی مصنوعی طراحیشده در نظر گرفته میشود. شبکه عصبیمصنوعی موردنظر مطابق با تصویر شماره 2، شبکه عصبی پیشخور با 3 ورودی، 20 لایه پنهان و 1 خروجی است.
در این مقاله، از مجموعه داده میرشریف و همکاران استفاده شده است [15]. این مجموعه داده مربوط به بیش از صد پرونده بیماران از سال 1390 تا 1393 در تحقیقی میدانی و نمونهگیری هدفمند از کلینیک پزشکی تخصصی زنان در تهران مورد بررسی قرار گرفت که از میان آنها 105 مورد دارای اطلاعات کامل از ابتدا تا انتهای بارداری بودند (80 نفر انسان سالم و 25 نفر انسان بیمار).
محیط شبیهسازی
در این مقاله، برای بررسی سیستم پیشنهادی و ارائه نتایج آن، پیادهسازی رویکرد پیشنهادشده به کمک زبانهایبرنامهنویسی انجام شده است. به این منظور، الگوریتم پیشنهادشده در محیط متلب نسخه R2016a پیادهسازی شده است. زبان برنامهنویسی متلب یکی از زبانهای مفسری است که بهطور گستردهای در رشتههای مهندسی استفادهمیشود. این محیط شبیهسازی شهرت خود را از قابلیت استفاده آسان خود به دست آورده است. آزمایشات در سیستمی با پردازنده INTEL CELERON D800 1.50 GHz و حافظهی داخلی 2 گیگابایت مورد تست و ارزیابی قرار گرفته است.
پارامترها
در الگوریتم پیشنهادی مطابق جدول شماره 1، تعداد تکرار 100 مرتبه، تعداد جمعیت اولیه 100 عدد، درصد عملیات تقاطع 7 و درصد عملیات جهش 3 در نظر گرفته شده است.
همچنین این الگوریتم با اجرای یک چرخ رولت عضوهای جمعیت را جهت عملیات تقاطع و جهش انتخاب میکند. پس از اجرای عملیاتهای تقاطع و جهش، فرزندهای بهدستآمده از این عملیاتها با استفاده از تابع ارزیابی بررسی میشوند. سپس این فرزندان با جمعیت قبلی ادغام شده و 100 فرد از این جمعیت که دارای مقدار ارزیابی بهتری هستند بهعنوان جمعیت جدید انتخاب میشوند. پس از صد تکرار فردی در جمعیت که دارای بهترین مقدار ارزیابی است بهعنوان بهترین فرد شناخته شده و پارتشین بهدستآمده از آن بهعنوان جواب مسئله در نظر گرفته میشود که این پارتیشن شامل خوشههایی از مجموعه داده ورودی است. سپس برچسبهای خوشههای بهدستآمده و مجموعه داده بهعنوان ورودی جهت عملیات یادگیری وارد شبکه عصبی پیشخور میشود. در شبکه عصبی طراحیشده، تعداد لایههای پنهان 20، نوع تابع تبدیل تابع سیگموئیدی و نرخ یادگیری و تست نیز به ترتیب 75 و 25 درصد تنظیم شده است.
یافتهها
نحوه انجام کار روش پیشنهادی
در این بخش، نحوه انجام کار روش پیشنهادی در محیط متلب توضیح داده میشود. در اینجا ابتدا عملیات خوشهبندی بدون نظارت جهت ایجاد 2 خوشه افراد سالم و بیمار با استفاده از الگوریتم ژنتیک بر روی مجموعه داده ورودی انجام میگیرد. سپس مجموعه داده ورودی و خروجی الگوریتم ژنتیک جهت انجام عملیات آموزش بهعنوان ورودی شبکه عصبی مصنوعی طراحیشده در نظر گرفته میشود. شبکه عصبیمصنوعی موردنظر مطابق با تصویر شماره 2، شبکه عصبی پیشخور با 3 ورودی، 20 لایه پنهان و 1 خروجی است.
همچنین تابع مورد استفاده در آن نیز تابع سیگموئیدی است.
در این تحقیق، بهطور پیشفرض جهت یادگیری سیستم 75 درصد از مجموعهی دادهها بهعنوان نمونههای یادگیری مورد استفاده قرار گرفت. همچنین بهمنظور بررسی کردن دقت سیستم از 25 درصد مجموعه داده بهعنوان تست و اعتبارسنجی استفاده شده است. مجموعه داده موردبررسی، مجموعه داده دیابت استفادهشده در مقاله میرشرف و همکاران بود که این مجموعه داده شامل 105 عضو بود (80 نمونه افراد سالم و 25 نمونه افراد بیمار) .
بررسی نحوه بهبود دقت آموزش سیستم
هدف از طراحی این آزمایش بررسی نحوه بهبود دقت سیستم است. برای انجام این کار سیستم با جمعیت 100، تکرار 100، ضریب تقاطع 0/7 و ضریب جهش 0/3 اجرا شده است. همچنین در شبکه عصبی طراحیشده، تعداد لایه پنهان 20، ورودی 3 و خروجی 1 است. در این آزمایش دادههای تست سیستم (برای ارزیابی سیستم و به دست آوردن دقت) با دادههای آموزش یکسان است و آزمایش موردنظر 100 مرتبه تکرار شده است. در این آزمایش نمودار بهبود در طی تکرارهای متوالی در متلب رسم شده است. همانطور که در تصویر 3 نشان داده شده است.
در این تحقیق، بهطور پیشفرض جهت یادگیری سیستم 75 درصد از مجموعهی دادهها بهعنوان نمونههای یادگیری مورد استفاده قرار گرفت. همچنین بهمنظور بررسی کردن دقت سیستم از 25 درصد مجموعه داده بهعنوان تست و اعتبارسنجی استفاده شده است. مجموعه داده موردبررسی، مجموعه داده دیابت استفادهشده در مقاله میرشرف و همکاران بود که این مجموعه داده شامل 105 عضو بود (80 نمونه افراد سالم و 25 نمونه افراد بیمار) .
بررسی نحوه بهبود دقت آموزش سیستم
هدف از طراحی این آزمایش بررسی نحوه بهبود دقت سیستم است. برای انجام این کار سیستم با جمعیت 100، تکرار 100، ضریب تقاطع 0/7 و ضریب جهش 0/3 اجرا شده است. همچنین در شبکه عصبی طراحیشده، تعداد لایه پنهان 20، ورودی 3 و خروجی 1 است. در این آزمایش دادههای تست سیستم (برای ارزیابی سیستم و به دست آوردن دقت) با دادههای آموزش یکسان است و آزمایش موردنظر 100 مرتبه تکرار شده است. در این آزمایش نمودار بهبود در طی تکرارهای متوالی در متلب رسم شده است. همانطور که در تصویر 3 نشان داده شده است.
سیستم پیشنهادی توانسته است بعد از گذشت 100 تکرار به دقت 0/98 دست پیداکند. برای به دست آوردن نمودار هموارتر میتوان سیستم را به تعداد دفعات بیشتر اجرا کرد و از نتایج دفعات مختلف میانگین گرفت و درنهایت روند بهبود را نمایش داد.
بررسی عملکرد سیستم با استفاده از دادههای آموزش
در این بخش ماتریس درهمریختگی و منحنی راک سیستم بعد از آموزش سیستم بررسی خواهد شد. برای انجام این کار، سیستم پیشنهادی با جمعیت 100، تکرار 100، ضریب تقاطع 0/7، ضریب جهش 0/3 و اندازه مجموعه داده 80 نمونه، آموزش دیده است. در این آزمایش از نمونههای آموزش، 65 نمونه متعلق به افراد سالم و 15 نمونه متعلق به افراد بیمار بود. تصویر شماره 4 بهترین کارایی بهدستآمده سیستم پیشنهادی را نشان میدهد.
بررسی عملکرد سیستم با استفاده از دادههای آموزش
در این بخش ماتریس درهمریختگی و منحنی راک سیستم بعد از آموزش سیستم بررسی خواهد شد. برای انجام این کار، سیستم پیشنهادی با جمعیت 100، تکرار 100، ضریب تقاطع 0/7، ضریب جهش 0/3 و اندازه مجموعه داده 80 نمونه، آموزش دیده است. در این آزمایش از نمونههای آموزش، 65 نمونه متعلق به افراد سالم و 15 نمونه متعلق به افراد بیمار بود. تصویر شماره 4 بهترین کارایی بهدستآمده سیستم پیشنهادی را نشان میدهد.
مطابق با این تصویر بهترین کارایی 0/0311 است. هر اندازه این مقدار پایینتر باشد نشان از کارایی بالای سیستم است.
در تصویر شماره 5 منحنی راک نشان داده شده است.
در تصویر شماره 5 منحنی راک نشان داده شده است.
راک معیاری است که برای بررسی کیفیت دستهبندیکنندهها مورد استفاده قرار میگیرد. برای هر کلاس دستهبندیکننده، مقادیر آستانهای بین صفر و 1 برای خروجیها به کار میرود. برای هر حد آستانه 2 مقدار نرخ مثبت واقعی و نرخ مثبت کاذب محاسبه میشود. در تصویر شماره 5 مشاهده میشود که همواره نرخ مثبت واقعی بیشتر از نرخ مثبت کاذب است.
در تصویر شماره 6، ماتریس درهمریختگی مربوط به یادگیری سیستم پیشنهادی نمایش داده شده است.
در تصویر شماره 6، ماتریس درهمریختگی مربوط به یادگیری سیستم پیشنهادی نمایش داده شده است.
در ماتریس اغتشاش سطرها نشانگر کلاس پیشبینی شده (کلاس خروجی) و ستونها نشاندهنده کلاس صحیح (کلاس هدف) هستند. سلولهای مورب نشان میدهد چند مقدار (و چه درصدی) از مشاهدات، نمونه شبکه آموزشدیده را بهدرستی تخمین زده است.
در تصویر شماره 6، 2 سلول مورب اولیه تعداد و درصد دستهبندی صحیح با استفاده از شبکه آموزشدیده را نشان میدهند. در این رقم، 2 سلول مورب اول، تعداد و درصد طبقهبندیهای صحیح را توسط شبکه آموزشدیده نشان میدهند. مطابق با نتایج، 64 نفر بهدرستی بهعنوان افراد سالم طبقهبندی شدهاند. این مطلب مطابق با 80 درصد کل نمونههاست. بهطور مشابه، 15 مورد بهدرستی بهعنوان افراد بیمار طبقهبندی شدهاند. این مطلب، مطابق با 18/8 درصد کل نمونههای آزمایشی است. 1 نمونه از افراد سالم بهاشتباه بیمار دستهبندی شدهاند و مطابق با 1/3 درصد کل 80 نمونه موجود است.
سیستم پیشنهادی، مطابق با ماتریس اغتشاش تولیدشده، از 65 پیشبینی افراد سالم، 98/5 درصد بهدرستی و 1/5 درصد بهاشتباه کلاسبندی شدهاند. از 15 پیشبینی افراد بیمار، 100 درصد بهدرستی کلاسبندی شدهاند. از 64 موارد افراد سالم، 100 درصد بهخوبی بهعنوان افراد سالم پیشبینی شده است. از 16 مورد افراد بیمار، 93/8 درصد بهدرستی بهعنوان بیمار و 6/3 درصد بهعنوان افراد سالم طبقهبندی شدهاند. بهطورکلی، 98/8 درصد از پیشبینیها درست هستند و 1/2 درصد طبقهبندیهای اشتباه هستند.
بررسی عملکرد سیستم با استفاده از دادههایتست
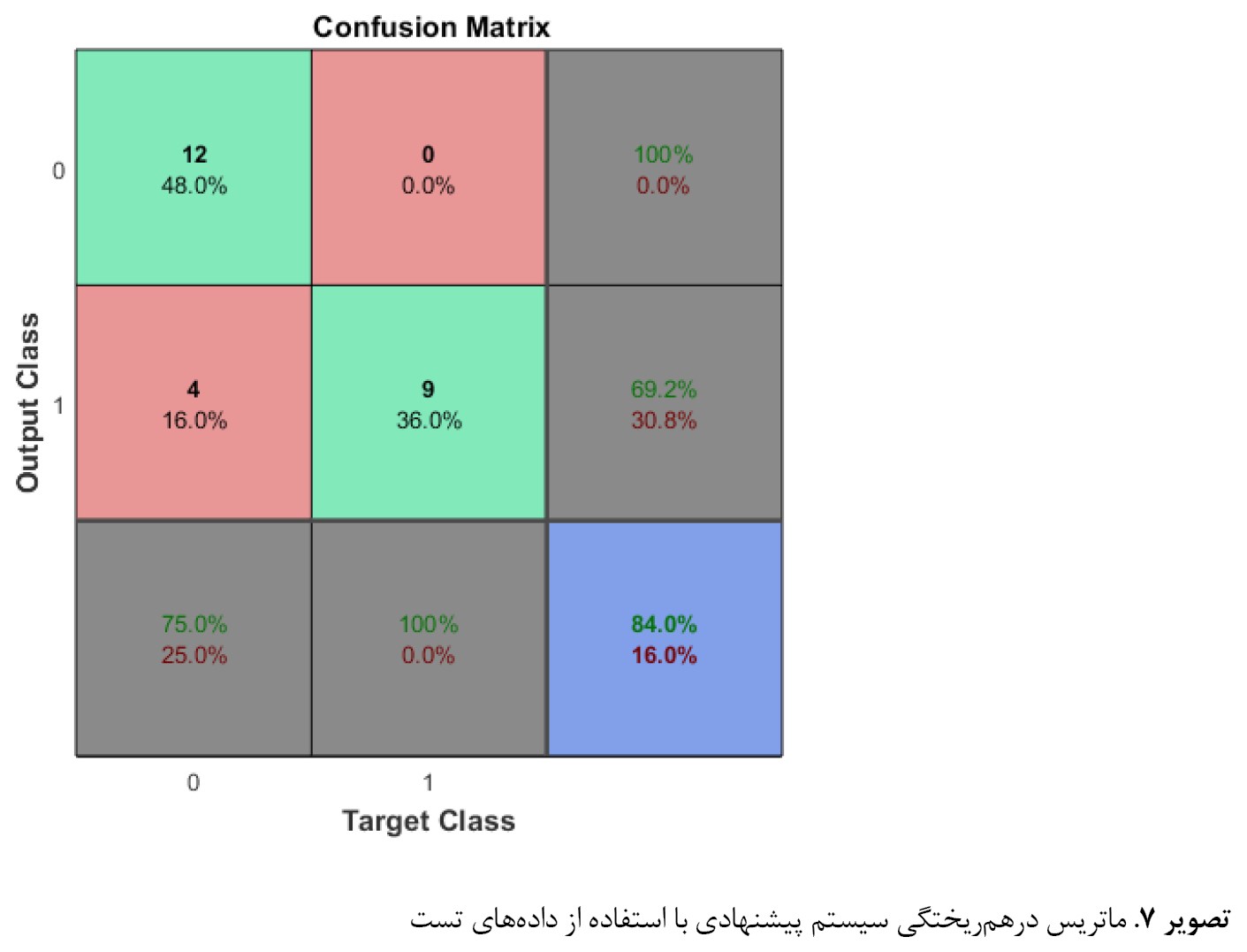
در این آزمایش، شبکه عصبی آموزشدیده آزمایش قبل، با دادههای تست ارزیابی شده است. در این آزمایش دادههای تست سیستم با دادههای آموزش یکسان نیست. در این تست از 25 نمونه برای ارزیابی سیستم استفاده شده است که از میان آنها 15 نمونه افراد سالم و 10 نمونه افراد بیمار بودند. در تصویر شماره 7 ماتریس درهمریختگی به ازای نمونههای تست ارائه شده است.
در تصویر شماره 6، 2 سلول مورب اولیه تعداد و درصد دستهبندی صحیح با استفاده از شبکه آموزشدیده را نشان میدهند. در این رقم، 2 سلول مورب اول، تعداد و درصد طبقهبندیهای صحیح را توسط شبکه آموزشدیده نشان میدهند. مطابق با نتایج، 64 نفر بهدرستی بهعنوان افراد سالم طبقهبندی شدهاند. این مطلب مطابق با 80 درصد کل نمونههاست. بهطور مشابه، 15 مورد بهدرستی بهعنوان افراد بیمار طبقهبندی شدهاند. این مطلب، مطابق با 18/8 درصد کل نمونههای آزمایشی است. 1 نمونه از افراد سالم بهاشتباه بیمار دستهبندی شدهاند و مطابق با 1/3 درصد کل 80 نمونه موجود است.
سیستم پیشنهادی، مطابق با ماتریس اغتشاش تولیدشده، از 65 پیشبینی افراد سالم، 98/5 درصد بهدرستی و 1/5 درصد بهاشتباه کلاسبندی شدهاند. از 15 پیشبینی افراد بیمار، 100 درصد بهدرستی کلاسبندی شدهاند. از 64 موارد افراد سالم، 100 درصد بهخوبی بهعنوان افراد سالم پیشبینی شده است. از 16 مورد افراد بیمار، 93/8 درصد بهدرستی بهعنوان بیمار و 6/3 درصد بهعنوان افراد سالم طبقهبندی شدهاند. بهطورکلی، 98/8 درصد از پیشبینیها درست هستند و 1/2 درصد طبقهبندیهای اشتباه هستند.
بررسی عملکرد سیستم با استفاده از دادههایتست
در این آزمایش، شبکه عصبی آموزشدیده آزمایش قبل، با دادههای تست ارزیابی شده است. در این آزمایش دادههای تست سیستم با دادههای آموزش یکسان نیست. در این تست از 25 نمونه برای ارزیابی سیستم استفاده شده است که از میان آنها 15 نمونه افراد سالم و 10 نمونه افراد بیمار بودند. در تصویر شماره 7 ماتریس درهمریختگی به ازای نمونههای تست ارائه شده است.
همانطور که نمودار ماتریس درهمریختگی نشان میدهد، سیستم توانسته به دقت تست 84 درصد دست پیدا کند. همچنین تعداد نمونههای افراد سالم نسبت به نمونههای افراد بیمار بهتر پیشبینی شدهاند. یکی از دلایل این اتفاق میتواند وجود تعداد نمونههای مثبت بیشتر در دادههای آموزش باشد.
مطابق با نتایج ماتریس اغتشاش در فرایند تست، تعداد 12 نمونه بهدرستی بهعنوان افراد سالم طبقهبندی شده است. این مطلب مطابق با 48 درصد کل 25 نمونه است. بهطور مشابه، 9 مورد بهدرستی بهعنوان افراد بیمار طبقهبندی شدهاند. این مطلب، مطابق با 36 درصد کل نمونههای آزمایشی است. هیچکدام از افراد سالم به اشتباه در افراد بیمار دستهبندی نشدهاند. اما 4 مورد از افراد بیمار در کلاس سالم قرار گرفتهاند که مطابق با 16 درصد کل نمونهها استد.
در تست سیستم پیشنهادی، مطابق با ماتریس اغتشاش تولیدشده، از 12 پیشبینی افراد سالم، 100 درصد بهدرستی کلاسبندی شدهاند. از 13 نمونه پیشبینی افراد بیمار، 69/2 درصد بهدرستی و 30/8 درصد بهاشتباه کلاسبندی شدهاند. از 16 نمونه افراد سالم، 75 درصد بهدرستی بهعنوان افراد سالم و 25 درصد بهعنوان افراد بیمار پیشبینی شده است. از 9 مورد افراد بیمار، 100 درصد بهدرستی بهعنوان بیمار طبقهبندی شدهاند. بهطورکلی، 84 درصد از پیشبینیها درست هستند و 16 درصد طبقهبندیهای اشتباه هستند.
مقایسه با تحقیقات انجامشده در سالهای اخیر
در این بخش سیستم پیشنهادی بر روی مجموعهداده مشابه، با سیستم پیشنهادشده میرشرف و همکاران جهت تشخیص دیابت بارداری ارزیابی شده است. در این آزمایش سیستم پیشنهادی و سیستم ارائهشده توسط میرشریف بر روی مجموعهداده مشابه (مجموعه داده مورداستفاده توسط میرشریف) اجراشده و کارایی آن با استفاده از متریکهای دقت [17 ،15] و میانگین مربعات خطا [19 ،18 ،15]، ارزیابی شده است. فرمول شماره 1 و 2 معیارهای موردارزیابی را نشان میدهد [15].

که در این روابط مقادیر TP، FP و FN به ترتیب برابر با تعداد نمونههای مثبت درست پیشبینیشده، تعداد نمونههای مثبت نادرست پیشبینیشده و تعداد نمونههای منفی نادرست پیشبینیشده هستند. همچنین Yi مقدار واقعی و Yi' مقدار پیشبینی است. درحقیقت معیار دقت، دقت سیستم موردنظر و معیار خطای میانگین مربعات میانگین اختلاف مقدار واقعی و مقدار پیشبینیشده توسط سیستم را به دست میآورند. در اینجا، معیار دقت هر اندازه بیشتر باشد سیستم بهینه خواهد بود. اما معیار میانگین مربعات خطا هر اندازه کمتر باشد، سیستم بهینه خواهد بود [20, 21].
در این بخش سیستم پیشنهادی بر روی مجموعهداده میرشریف اعمال شده است. مطابق با جدول شماره 2، کارایی و عملکرد روش پیشنهادی از روش ارائهشده توسط میرشریف در هر دو معیار خطای میانگین مربعات و دقت بهتر است.
.jpg)
این نشان میدهد که روش پیشنهادی در حالت بدون نظارت کارایی مطلوب را در مواجهه با مجموعه دادههای مختلف بهمنظور تشخیص دقیق دیابت داراست.
بحث
در این پژوهش رویکردی هوشمند و بدون نظارت، جهت تشخیص بیماری دیابت بارداری ارائه شد. روش پیشنهادی به دنبال بهبود فرایند پیشبینی افراد داری دیابت بارداری از افراد سالم بود. در همین راستا، زاهدیفرد و همکاران، با استفاده از دادهکاوی، افراد دیابتی را خوشهبندی و براساس تفسیرهای هرخوشه الگوهایی برای افراد دیابتی استخراج کردند [14].
همچنین میرشریف و همکاران، سطح هشدار بهموقع در ابتلا به دیابت بارداری در مادران را بررسی کردند. در این پژوهش با استفاده از شبکه عصبی و درخت تصمیم، روشی جهت پیشبینی پیشنهاد شد [15].
زیبا خوشناموند و همکارانش نیز پژوهشی با عنوان «تشخیص دیابت به کمک الگوریتم بهینهسازی امواج آب و مقایسه آن با الگوریتمهای یادگیری ماشین» انجام دادند. در این پژوهش یک روش برای تشخیص بیماری دیابت به کمک شبکه عصبی مصنوعی با استفاده از الگوریتم فراابتکاری بهینهسازی امواج آب ارائه شد [16].
نتیجهگیری
در تمامی این پژوهشها، روشهای ارائهشده همگی قادر به تشخیص و پیشبینی، بیماران دیابتی با استفاده از راهکارهای بانظارت هستند. اما در واقعیت، راهکارهای با نظارت نمیتوانند الگوهای مناسب پیشبینی را کشف کنند [22, 23]. به همین منظور، در این پژوهش سعی شده، رویکردی هوشمند و بدون نظارت، مبتنی بر تکنیکهای شبکه عصبیمصنوعی و الگوریتم ژنتیک جهت پیشبینی بیماران دیابت بارداری ارائه شود.
شبکه عصبی موجود در روش پیشنهادی الگوهای پنهان در افراد بیمار را نسبت به افراد سالم با بررسی مجموعه داده موردنظر کشف میکند. ازآنجاکه نحوه عملکرد شبکه عصبی به چگونگی تعریف ساختار آن بستگی دارد [24, 25]، در این تحقیق در کنار شبکه عصبی پیشنهادشده، از الگوریتم ژنتیک استفاده شده است که وظیفه آن یادگیری بدون نظارت ساختار شبکه عصبی است.
سیستم پیشنهادی در محیط متلب پیادهسازی و عملکرد آن ارزیابی شده است. نتایج پیادهسازی سیستم پیشنهادی نشان داده است که عملکرد و دقت الگوریتم در مجموعه داده موردنظر و همچنین نسبت به سیستم مشابه قبلی، قابلقبول بوده و بهطور قابلتوجهی بهبود پیدا کرده است. علاوه بر این نتایج مقایسه سیستم پیشنهادی با روش موجود در حوزه تحقیق نشان داد، سیستم پیشنهادی توانسته است در معیارهای مختلف به بهبود قابلملاحظهای دست یابد.
ازجمله محدودیتهای موجود در این پژوهش، میتوان به مدل یادگیر موردنظر اشاره کرد. مدل یادگیر شبکه عصبی بهشدت وابسته به نوع داده دستهبندیشده ورودی است. در اینجا، از الگوریتم ژنتیک برای دستهبندی داده ورودی استفاده شده است، ازآنجاییکه یکی از محدودیتهای الگوریتم ژنتیک، شناسایی دقیق نقطه بهینه در فضای جواب است، پس میتوان ایجاد دستهبندی دقیق مجموعه داده ورودی را بهعنوان محدودیت روش پیشنهادی دانست. همچنین بهعنوان پیشنهاد کارهای آتی نیز میتوان به جایگزین کردن دیگر الگوریتمهای تکاملی نظیر الگوریتم بهینهسازی ازدحام ذرات و الگوریتم کلونی مورچگان بهجای الگوریتم ژنتیک، در جهت بهبود فرایند دستهبندی مجموعه داده ورودی اشاره کرد.
ملاحظات اخلاقی
پیروی از اصول اخلاق پژوهش
این مطالعه دارای تأییدیه اخلاقی به شماره 1144819916004881397187659556 از دانشگاه آزاد اسلامی واحد استهبان است.
حامی مالی
این مقاله از طرف هیچ نهاد یا مؤسسهای حمایت مالی نشده است و منابع مالی از طرف نویسنده تأمین شده است.
مشارکت نویسندگان
محمدجوادحسینپور نویسنده مسئول این مقاله، تمامی مراحل تحقیق و تدوین این مقاله را انجام داده است.
تعارض منافع
بنابر اظهار نویسنده این مقاله تعارض منافع ندارد.
تشکر و قدردانی
نویسنده مقاله بر خود لازم میداند از همکاری و مساعدت دانشگاه آزاد اسلامی واحد استهبان سپاسگزاری کند.
مطابق با نتایج ماتریس اغتشاش در فرایند تست، تعداد 12 نمونه بهدرستی بهعنوان افراد سالم طبقهبندی شده است. این مطلب مطابق با 48 درصد کل 25 نمونه است. بهطور مشابه، 9 مورد بهدرستی بهعنوان افراد بیمار طبقهبندی شدهاند. این مطلب، مطابق با 36 درصد کل نمونههای آزمایشی است. هیچکدام از افراد سالم به اشتباه در افراد بیمار دستهبندی نشدهاند. اما 4 مورد از افراد بیمار در کلاس سالم قرار گرفتهاند که مطابق با 16 درصد کل نمونهها استد.
در تست سیستم پیشنهادی، مطابق با ماتریس اغتشاش تولیدشده، از 12 پیشبینی افراد سالم، 100 درصد بهدرستی کلاسبندی شدهاند. از 13 نمونه پیشبینی افراد بیمار، 69/2 درصد بهدرستی و 30/8 درصد بهاشتباه کلاسبندی شدهاند. از 16 نمونه افراد سالم، 75 درصد بهدرستی بهعنوان افراد سالم و 25 درصد بهعنوان افراد بیمار پیشبینی شده است. از 9 مورد افراد بیمار، 100 درصد بهدرستی بهعنوان بیمار طبقهبندی شدهاند. بهطورکلی، 84 درصد از پیشبینیها درست هستند و 16 درصد طبقهبندیهای اشتباه هستند.
مقایسه با تحقیقات انجامشده در سالهای اخیر
در این بخش سیستم پیشنهادی بر روی مجموعهداده مشابه، با سیستم پیشنهادشده میرشرف و همکاران جهت تشخیص دیابت بارداری ارزیابی شده است. در این آزمایش سیستم پیشنهادی و سیستم ارائهشده توسط میرشریف بر روی مجموعهداده مشابه (مجموعه داده مورداستفاده توسط میرشریف) اجراشده و کارایی آن با استفاده از متریکهای دقت [17 ،15] و میانگین مربعات خطا [19 ،18 ،15]، ارزیابی شده است. فرمول شماره 1 و 2 معیارهای موردارزیابی را نشان میدهد [15].
که در این روابط مقادیر TP، FP و FN به ترتیب برابر با تعداد نمونههای مثبت درست پیشبینیشده، تعداد نمونههای مثبت نادرست پیشبینیشده و تعداد نمونههای منفی نادرست پیشبینیشده هستند. همچنین Yi مقدار واقعی و Yi' مقدار پیشبینی است. درحقیقت معیار دقت، دقت سیستم موردنظر و معیار خطای میانگین مربعات میانگین اختلاف مقدار واقعی و مقدار پیشبینیشده توسط سیستم را به دست میآورند. در اینجا، معیار دقت هر اندازه بیشتر باشد سیستم بهینه خواهد بود. اما معیار میانگین مربعات خطا هر اندازه کمتر باشد، سیستم بهینه خواهد بود [20, 21].
در این بخش سیستم پیشنهادی بر روی مجموعهداده میرشریف اعمال شده است. مطابق با جدول شماره 2، کارایی و عملکرد روش پیشنهادی از روش ارائهشده توسط میرشریف در هر دو معیار خطای میانگین مربعات و دقت بهتر است.
این نشان میدهد که روش پیشنهادی در حالت بدون نظارت کارایی مطلوب را در مواجهه با مجموعه دادههای مختلف بهمنظور تشخیص دقیق دیابت داراست.
بحث
در این پژوهش رویکردی هوشمند و بدون نظارت، جهت تشخیص بیماری دیابت بارداری ارائه شد. روش پیشنهادی به دنبال بهبود فرایند پیشبینی افراد داری دیابت بارداری از افراد سالم بود. در همین راستا، زاهدیفرد و همکاران، با استفاده از دادهکاوی، افراد دیابتی را خوشهبندی و براساس تفسیرهای هرخوشه الگوهایی برای افراد دیابتی استخراج کردند [14].
همچنین میرشریف و همکاران، سطح هشدار بهموقع در ابتلا به دیابت بارداری در مادران را بررسی کردند. در این پژوهش با استفاده از شبکه عصبی و درخت تصمیم، روشی جهت پیشبینی پیشنهاد شد [15].
زیبا خوشناموند و همکارانش نیز پژوهشی با عنوان «تشخیص دیابت به کمک الگوریتم بهینهسازی امواج آب و مقایسه آن با الگوریتمهای یادگیری ماشین» انجام دادند. در این پژوهش یک روش برای تشخیص بیماری دیابت به کمک شبکه عصبی مصنوعی با استفاده از الگوریتم فراابتکاری بهینهسازی امواج آب ارائه شد [16].
نتیجهگیری
در تمامی این پژوهشها، روشهای ارائهشده همگی قادر به تشخیص و پیشبینی، بیماران دیابتی با استفاده از راهکارهای بانظارت هستند. اما در واقعیت، راهکارهای با نظارت نمیتوانند الگوهای مناسب پیشبینی را کشف کنند [22, 23]. به همین منظور، در این پژوهش سعی شده، رویکردی هوشمند و بدون نظارت، مبتنی بر تکنیکهای شبکه عصبیمصنوعی و الگوریتم ژنتیک جهت پیشبینی بیماران دیابت بارداری ارائه شود.
شبکه عصبی موجود در روش پیشنهادی الگوهای پنهان در افراد بیمار را نسبت به افراد سالم با بررسی مجموعه داده موردنظر کشف میکند. ازآنجاکه نحوه عملکرد شبکه عصبی به چگونگی تعریف ساختار آن بستگی دارد [24, 25]، در این تحقیق در کنار شبکه عصبی پیشنهادشده، از الگوریتم ژنتیک استفاده شده است که وظیفه آن یادگیری بدون نظارت ساختار شبکه عصبی است.
سیستم پیشنهادی در محیط متلب پیادهسازی و عملکرد آن ارزیابی شده است. نتایج پیادهسازی سیستم پیشنهادی نشان داده است که عملکرد و دقت الگوریتم در مجموعه داده موردنظر و همچنین نسبت به سیستم مشابه قبلی، قابلقبول بوده و بهطور قابلتوجهی بهبود پیدا کرده است. علاوه بر این نتایج مقایسه سیستم پیشنهادی با روش موجود در حوزه تحقیق نشان داد، سیستم پیشنهادی توانسته است در معیارهای مختلف به بهبود قابلملاحظهای دست یابد.
ازجمله محدودیتهای موجود در این پژوهش، میتوان به مدل یادگیر موردنظر اشاره کرد. مدل یادگیر شبکه عصبی بهشدت وابسته به نوع داده دستهبندیشده ورودی است. در اینجا، از الگوریتم ژنتیک برای دستهبندی داده ورودی استفاده شده است، ازآنجاییکه یکی از محدودیتهای الگوریتم ژنتیک، شناسایی دقیق نقطه بهینه در فضای جواب است، پس میتوان ایجاد دستهبندی دقیق مجموعه داده ورودی را بهعنوان محدودیت روش پیشنهادی دانست. همچنین بهعنوان پیشنهاد کارهای آتی نیز میتوان به جایگزین کردن دیگر الگوریتمهای تکاملی نظیر الگوریتم بهینهسازی ازدحام ذرات و الگوریتم کلونی مورچگان بهجای الگوریتم ژنتیک، در جهت بهبود فرایند دستهبندی مجموعه داده ورودی اشاره کرد.
ملاحظات اخلاقی
پیروی از اصول اخلاق پژوهش
این مطالعه دارای تأییدیه اخلاقی به شماره 1144819916004881397187659556 از دانشگاه آزاد اسلامی واحد استهبان است.
حامی مالی
این مقاله از طرف هیچ نهاد یا مؤسسهای حمایت مالی نشده است و منابع مالی از طرف نویسنده تأمین شده است.
مشارکت نویسندگان
محمدجوادحسینپور نویسنده مسئول این مقاله، تمامی مراحل تحقیق و تدوین این مقاله را انجام داده است.
تعارض منافع
بنابر اظهار نویسنده این مقاله تعارض منافع ندارد.
تشکر و قدردانی
نویسنده مقاله بر خود لازم میداند از همکاری و مساعدت دانشگاه آزاد اسلامی واحد استهبان سپاسگزاری کند.
References
1.Mierzyński R, Poniedziałek-Czajkowska E, Dłuski D, Patro-Małysza J, Kimber-Trojnar Ż, Majsterek M, et al. Nesfatin-1 and vaspin as potential novel biomarkers for the prediction and early diagnosis of gestational Diabetes Mellitus. Int J Mol Sci. 2019; 20(1):159. [PMID]
2.Pei T, Wang W, Zhang H, Ma T, Du Y, Zhou C. Density-based clustering for data containing two types of pointsInt J Geogr Inf Sci. 2015; 29(2):175-93. [DOI:10.1080/13658816.2014.955027]
3.Jayalakshmi T, Santhakumaran A. A novel classification method for diagnosis of Diabetes Mellitus using artificial neural networks. Paper presented at: International Conference on Data Storage and Data Engineering. 9-10 February 2010; Bangalore, India. [DOI:10.1109/DSDE.2010.58]
4.Kumar D, Palaniswami M, Rajasegarar S, Leckie C, Bezdek JC, Havens TC. clusiVAT: A mixed visual/numerical clustering algorithm for big data. Paper presented at: IEEE International Conference on Big Data. 6-9 October 2013; Silicon Valley, USA. [DOI:10.1109/BigData.2013.6691561]
5.Zhao L, Ren Y. A scalable genetic algorithm for discovering comprehensible anomaly detection rules using big data in computer cluster. Paper presented at: 3rd International Conference on Systems and Informatics (ICSAI). 19-21 November 2016; Shanghai, China. [DOI:10.1109/ICSAI.2016.7811048]
6.Johnson T, Kumar Singh S. Enhanced K Strange points clustering algorithm. Paper presented at: International Conference on Emerging Information Technology and Engineering Solutions. 20-21 February 2015; Washington, DC, United States. [DOI:10.1109/EITES.2015.14]
7.Schneider AK, Leemaqz SY, Dalton J, Verburg PE, Mol BW, Dekker GA, et al. The interaction between metabolic syndrome and physical activity, and risk for gestational Diabetes Mellitus. Acta Diabetol. 2021; 58(7):939-47. [PMID]
8.Berikov V. Weighted ensemble of algorithms for complex data clustering. Pattern Recognit Lett. 2014; 38:99-106. [DOI:10.1016/j.patrec.2013.11.012]
9.Khan SR, Mohan H, Liu Y, Batchuluun B, Gohil H, Al Rijjal D, et al. Correction to: The discovery of novel predictive biomarkers and early-stage pathophysiology for the transition from gestational diabetes to type 2 diabetes. Diabetologia. 2019; 62(4):730-1. [PMID]
10.Breuing J, Pieper D, Neuhaus AL, Heß S, Lütkemeier L, Haas F, et al. Barriers and facilitating factors in the prevention of diabetes type II and gestational diabetes in vulnerable groups: protocol for a scoping review. Syst Rev. 2018; 7(1):245. [PMID]
11.Parsons J, Sparrow K, Ismail K, Hunt K, Rogers H, Forbes A. Experiences of gestational diabetes and gestational diabetes care: A focus group and interview study. BMC Pregnancy Childbirth. 2018; 18(1):25. [PMID]
12.Hosseinpoor M, Parvin H, Nejatian S, Rezaei V. [Detection and extraction of potential promoter/enhancer interactions in genome of cancer patients using an evolutionary multi-objective algorithm (Persian)]. J Health Biomed Inform. 2018; 5(2):304-13. [Link]
13.Mohammadi F, Nazari S. [Exodite segmentation in diabetic patients in retinal images using fuzzy clustering (Persian)]. Papaer presented at: 3rd International Congress on Computer, Electrical and Telecommunication. 22 September 2016; Torbat Heydariyeh, Iran. [Link]
14.Zahedi Fard MR, Malekzadeh ـJ, Habibi S. [Medical data mining: Pattern discovery for diabetics using significant variables in diabetes (Persian)]. Paper presented at: 12th National Conference on Intelligent Systems, Bam, Iranian Intelligent Systems Association. 3-5 February 2014; Bam, Iran. [Link]
15.Mirsharif M, Rouhani S. [Data mining approach based on neural network and decision tree methods for the early diagnosis of risk of gestational Diabetes Mellitus (Persian)]. J Health Biomed Inform. 2017; 4(1):59-68. [Link]
16.Khoshnamvand Z, Asadi F, Khoshnamvand S, Khoshnamvand M. Diagnosis of diabetes using water wave optimization algorithm and comparison with machine learning algorithms. Paper presented at: 5th International Conference on Knowledge Based Research in Computer Engineering and Information Technology. 21 July 2017; Tehran, Iran. [Link]
17.Sun H, Saeedi P, Karuranga S, Pinkepank M, Ogurtsova K, Duncan BB, et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res Clin Pract. 2022; 183:109119. [PMID]
18.Pouya S, Petersohn I, Salpea P, Malanda B, Karuranga S, Unwin N, et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas, 9(th) edition. Diabetes Res Clin Pract. 2019; 157:107843. [DOI:10.1016/j.diabres.2019.107843]
19.Stotz SA, McNealy K, Begay RL, DeSanto K, Manson SM, Moore KR. Multi-level diabetes prevention and treatment interventions for native people in the USA and Canada: A scoping review. Curr Diab Rep. 2021; 21(11):46. [PMID]
20.Teufel NI, Ritenbaugh CK. Development of a primary prevention program: insight gained in the Zuni Diabetes Prevention Program. Clin Pediatr (Phila). 1998; 37(2):131-41.[PMID]
21.Chambers RA, Rosenstock S, Neault N, Kenney A, Richards J, Begay K, et al. A home-visiting diabetes prevention and management program for American Indian Youth: The together on Diabetes trial. Diabetes Educ. 2015; 41(6):729-47. [PMID]
22.Hosseinpoor MJ, Parvin H, Nejatian S, Rezaie V. Gene regulatory elements extraction in breast cancer by Hi-C data using a meta-heuristic method. Russ J Genet. 2019; 55(9):1152-64. [DOI:10.1134 /S1022795419090072]
23.Kulhawy-Wibe S, King-Shier KM, Barnabe C, Manns BJ, Hemmelgarn BR, Campbell DJT. Exploring structural barriers to diabetes self-management in Alberta First Nations communities. Diabetol Metab Syndr. 2018; 10:87. [PMID]
24.HAPO Study Cooperative Research Group. Hyperglycemia and Adverse Pregnancy Outcome (HAPO) Study: Associations with neonatal anthropometrics. Diabetes. 2009; 58(2):453-9. [PMID]
25.Marais C, Hall DR, van Wyk L, Conradie M. Randomized cross-over trial comparing the diagnosis of gestational diabetes by oral glucose tolerance test and a designed breakfast glucose profile. Int J Gynaecol Obstet. 2018; 141(1):85-90.[PMID]
2.Pei T, Wang W, Zhang H, Ma T, Du Y, Zhou C. Density-based clustering for data containing two types of pointsInt J Geogr Inf Sci. 2015; 29(2):175-93. [DOI:10.1080/13658816.2014.955027]
3.Jayalakshmi T, Santhakumaran A. A novel classification method for diagnosis of Diabetes Mellitus using artificial neural networks. Paper presented at: International Conference on Data Storage and Data Engineering. 9-10 February 2010; Bangalore, India. [DOI:10.1109/DSDE.2010.58]
4.Kumar D, Palaniswami M, Rajasegarar S, Leckie C, Bezdek JC, Havens TC. clusiVAT: A mixed visual/numerical clustering algorithm for big data. Paper presented at: IEEE International Conference on Big Data. 6-9 October 2013; Silicon Valley, USA. [DOI:10.1109/BigData.2013.6691561]
5.Zhao L, Ren Y. A scalable genetic algorithm for discovering comprehensible anomaly detection rules using big data in computer cluster. Paper presented at: 3rd International Conference on Systems and Informatics (ICSAI). 19-21 November 2016; Shanghai, China. [DOI:10.1109/ICSAI.2016.7811048]
6.Johnson T, Kumar Singh S. Enhanced K Strange points clustering algorithm. Paper presented at: International Conference on Emerging Information Technology and Engineering Solutions. 20-21 February 2015; Washington, DC, United States. [DOI:10.1109/EITES.2015.14]
7.Schneider AK, Leemaqz SY, Dalton J, Verburg PE, Mol BW, Dekker GA, et al. The interaction between metabolic syndrome and physical activity, and risk for gestational Diabetes Mellitus. Acta Diabetol. 2021; 58(7):939-47. [PMID]
8.Berikov V. Weighted ensemble of algorithms for complex data clustering. Pattern Recognit Lett. 2014; 38:99-106. [DOI:10.1016/j.patrec.2013.11.012]
9.Khan SR, Mohan H, Liu Y, Batchuluun B, Gohil H, Al Rijjal D, et al. Correction to: The discovery of novel predictive biomarkers and early-stage pathophysiology for the transition from gestational diabetes to type 2 diabetes. Diabetologia. 2019; 62(4):730-1. [PMID]
10.Breuing J, Pieper D, Neuhaus AL, Heß S, Lütkemeier L, Haas F, et al. Barriers and facilitating factors in the prevention of diabetes type II and gestational diabetes in vulnerable groups: protocol for a scoping review. Syst Rev. 2018; 7(1):245. [PMID]
11.Parsons J, Sparrow K, Ismail K, Hunt K, Rogers H, Forbes A. Experiences of gestational diabetes and gestational diabetes care: A focus group and interview study. BMC Pregnancy Childbirth. 2018; 18(1):25. [PMID]
12.Hosseinpoor M, Parvin H, Nejatian S, Rezaei V. [Detection and extraction of potential promoter/enhancer interactions in genome of cancer patients using an evolutionary multi-objective algorithm (Persian)]. J Health Biomed Inform. 2018; 5(2):304-13. [Link]
13.Mohammadi F, Nazari S. [Exodite segmentation in diabetic patients in retinal images using fuzzy clustering (Persian)]. Papaer presented at: 3rd International Congress on Computer, Electrical and Telecommunication. 22 September 2016; Torbat Heydariyeh, Iran. [Link]
14.Zahedi Fard MR, Malekzadeh ـJ, Habibi S. [Medical data mining: Pattern discovery for diabetics using significant variables in diabetes (Persian)]. Paper presented at: 12th National Conference on Intelligent Systems, Bam, Iranian Intelligent Systems Association. 3-5 February 2014; Bam, Iran. [Link]
15.Mirsharif M, Rouhani S. [Data mining approach based on neural network and decision tree methods for the early diagnosis of risk of gestational Diabetes Mellitus (Persian)]. J Health Biomed Inform. 2017; 4(1):59-68. [Link]
16.Khoshnamvand Z, Asadi F, Khoshnamvand S, Khoshnamvand M. Diagnosis of diabetes using water wave optimization algorithm and comparison with machine learning algorithms. Paper presented at: 5th International Conference on Knowledge Based Research in Computer Engineering and Information Technology. 21 July 2017; Tehran, Iran. [Link]
17.Sun H, Saeedi P, Karuranga S, Pinkepank M, Ogurtsova K, Duncan BB, et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res Clin Pract. 2022; 183:109119. [PMID]
18.Pouya S, Petersohn I, Salpea P, Malanda B, Karuranga S, Unwin N, et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas, 9(th) edition. Diabetes Res Clin Pract. 2019; 157:107843. [DOI:10.1016/j.diabres.2019.107843]
19.Stotz SA, McNealy K, Begay RL, DeSanto K, Manson SM, Moore KR. Multi-level diabetes prevention and treatment interventions for native people in the USA and Canada: A scoping review. Curr Diab Rep. 2021; 21(11):46. [PMID]
20.Teufel NI, Ritenbaugh CK. Development of a primary prevention program: insight gained in the Zuni Diabetes Prevention Program. Clin Pediatr (Phila). 1998; 37(2):131-41.[PMID]
21.Chambers RA, Rosenstock S, Neault N, Kenney A, Richards J, Begay K, et al. A home-visiting diabetes prevention and management program for American Indian Youth: The together on Diabetes trial. Diabetes Educ. 2015; 41(6):729-47. [PMID]
22.Hosseinpoor MJ, Parvin H, Nejatian S, Rezaie V. Gene regulatory elements extraction in breast cancer by Hi-C data using a meta-heuristic method. Russ J Genet. 2019; 55(9):1152-64. [DOI:10.1134 /S1022795419090072]
23.Kulhawy-Wibe S, King-Shier KM, Barnabe C, Manns BJ, Hemmelgarn BR, Campbell DJT. Exploring structural barriers to diabetes self-management in Alberta First Nations communities. Diabetol Metab Syndr. 2018; 10:87. [PMID]
24.HAPO Study Cooperative Research Group. Hyperglycemia and Adverse Pregnancy Outcome (HAPO) Study: Associations with neonatal anthropometrics. Diabetes. 2009; 58(2):453-9. [PMID]
25.Marais C, Hall DR, van Wyk L, Conradie M. Randomized cross-over trial comparing the diagnosis of gestational diabetes by oral glucose tolerance test and a designed breakfast glucose profile. Int J Gynaecol Obstet. 2018; 141(1):85-90.[PMID]
ارسال پیام به نویسنده مسئول
| بازنشر اطلاعات | |
 |
این مقاله تحت شرایط Creative Commons Attribution-NonCommercial 4.0 International License قابل بازنشر است. |
